
Harnessing AI for Intelligent PDF Processing in Swift: From OCR to Context-Aware Chunking
Learn how to harness AI to build an intelligent PDF processing app in Swift that employs advanced OCR, context-aware chunking, and a chain-of-agents architecture to extract and synthesize precise info

Working with PDF documents + AI models presents several challenges that need to be addressed:
OCR Conversion: The PDF document needs to be converted into text format, especially if it’s scanned or image-based.
Chunking for LLMs: Due to the limited context windows of Large Language Models (LLMs), the extracted text must be split into smaller chunks for processing.
Loss of Context: Breaking the document into chunks can result in a loss of the full context. For example, relevant information to the user’s query may be divided across pages—one part on page 1 (chunk 1) and another on page 100 (chunk 10) —making it harder to assemble the complete answer.
However, recently I stumbled upon two fascinating resources that make this process super easy in Swift:
Sergey Filimonov’s blog post: Ingesting Millions of PDFs and why Gemini 2.0 Changes Everything
Rudrank Riyam’s Chain-of-Agents implementation in Python + Swift
Inspired by these innovative approaches, I decided to experiment by combining them to create an app that queries PDFs solely in Swift.
OCR Conversion
There are several Swift SDKs that can work to extract text from PDFs, such as PSPDFKit (now Nutrient), PDFKit, and even the Vision Framework. However, these solutions generally process documents on a page-by-page basis, which can lead to a loss of context—for example, a sentence might begin at the end of one page and continue on the next. Additionally, they typically output text as plain or rich text, making it more challenging to convert to other formats like HTML or Markdown if needed.
Overall, these solutions are reliable and effective. If your app’s workflow involves working with PDFs on a page-by-page basis, they should be more than sufficient for your needs.
Chunking for LLMs
When working with entire PDF documents, you may need a more advanced chunking strategy that divides the document based on contextual relevance rather than just by pages or paragraphs. This is where LLMs can play a role. However, using LLMs for chunking PDFs has been challenging due to two main factors:
Context Window Limitations: LLMs have relatively short context windows. This means you must first pre-split the PDF, then use the LLM to further divide those chunks into contextually coherent segments, all while managing overlapping chunks in this multi-step process.
Cost: Since LLMs are priced per input and output token, processing large volumes of text can quickly become cost-prohibitive.
Together, these challenges have made it difficult to leverage LLMs for contextual chunking of entire PDFs—until now.
Google recently released the Gemini 2.0 Flash model, which supports a 1 MILLION token context window, is extremely cost effective, and performs super well in OCR + chunking. In fact - it is free to try until February 24th.
Beyond chunking, Gemini 2.0 Flash can effortlessly convert your content into any desired format—be it HTML, Markdown, or others. It just takes a few lines of code.
Loss of Context
I was excited to see Rudrank Riyam’s implementation of the new Chain-of-Agents implementation of Google’s paper of this concept. The concept is actually super simple and makes a lot of sense in retrospect. The steps are as follows as illustrated in Google’s diagram:
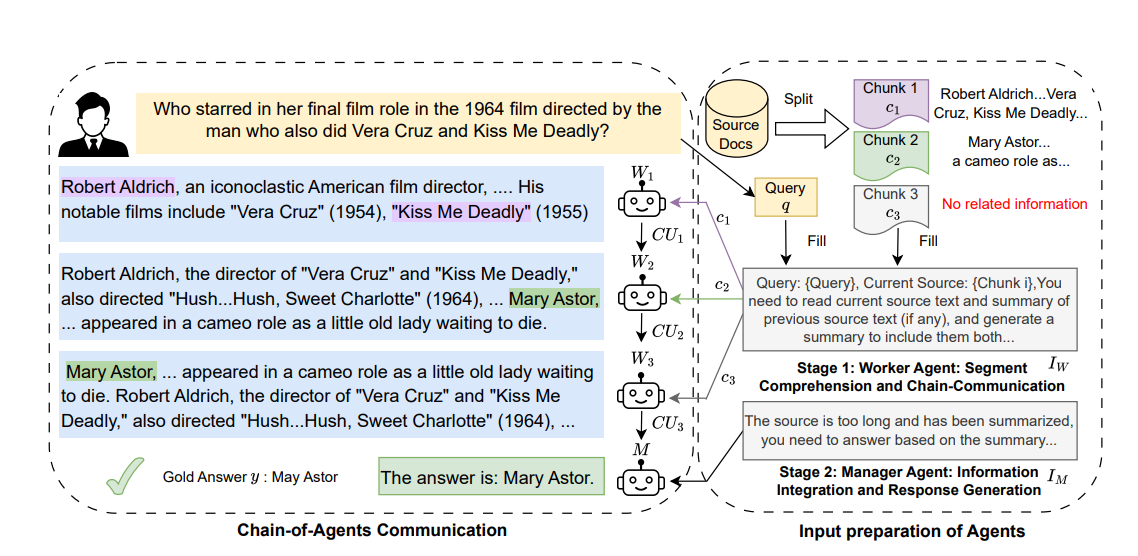
Split the Document: The PDF (or any lengthy document) is divided into smaller, more manageable chunks.
User Query: The user submits a question or query about specific information in the document.
Worker Agents: Each document chunk is handed off to a “Worker Agent” along with the user query. The agent identifies and extracts the information most relevant to the query—referred to as a Cognitive Unit (CU)—and then passes the CU, along with the next chunk and the user query, to the subsequent agent. This process repeats until all chunks have been processed.
Manager Agent: The “Manager Agent” receives all the relevant outputs from the Worker Agents and synthesizes them into a comprehensive final answer to the user’s query.
That’s it! Now that we’ve grasped the concept, let’s see what this looks like in a Swift application:
Building a PDFQuery App
To showcase this concept, I developed a simple Mac app that lets users upload a PDF and ask any question about its contents. For demonstration purposes, the app displays each individual chunk along with its corresponding output, as well as the final answer.
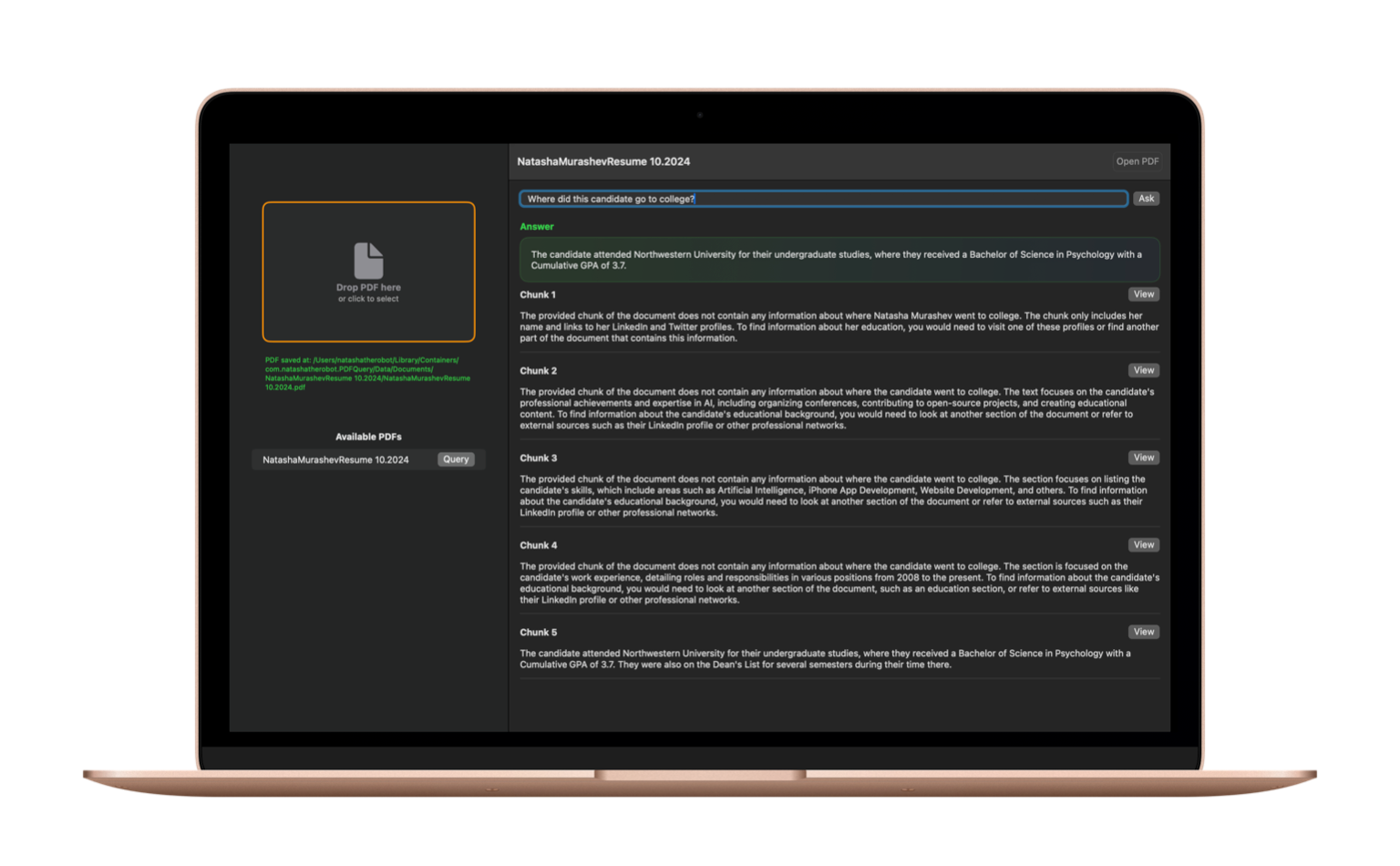
In this example, I uploaded my resume and asked the app to retrieve specific information from it. Because a resume is relatively short, it typically doesn’t require chunking and can easily fit within Gemini 2.0 Flash’s 1-million-token context window. However, this demonstration shows how the approach scales for larger documents or for models with smaller context windows, which may be better suited for specific queries.
Another consideration with large context windows is the increased risk of hallucination, especially when referencing content buried deep within the document. Even with a 1-million-token capacity, you may not always get the best results. In some cases, a Chain-of-Agents architecture could prove more effective. Ultimately, your choice will depend on your application’s requirements, document types, and the nature of the information you need to extract. Whatever your use-case, make sure to experiment with different prompts, architectures, and models to understand the right combination to find the combination that best suits your app’s specific needs.
The complete repository and code are available exclusively to our paid subscribers. However, the concepts outlined here are open to everyone—so feel free to use these ideas as a blueprint to build your own app.
Note that in this code sample, I’ll be using the AIProxy AIProxySwift library. This library is good for two purposes - it securely stores your AI service API keys on the server to protect them from hackers. And it provides SDKs for many AI services, making it easy to work across models as needed.
OCR and Chunk the Document
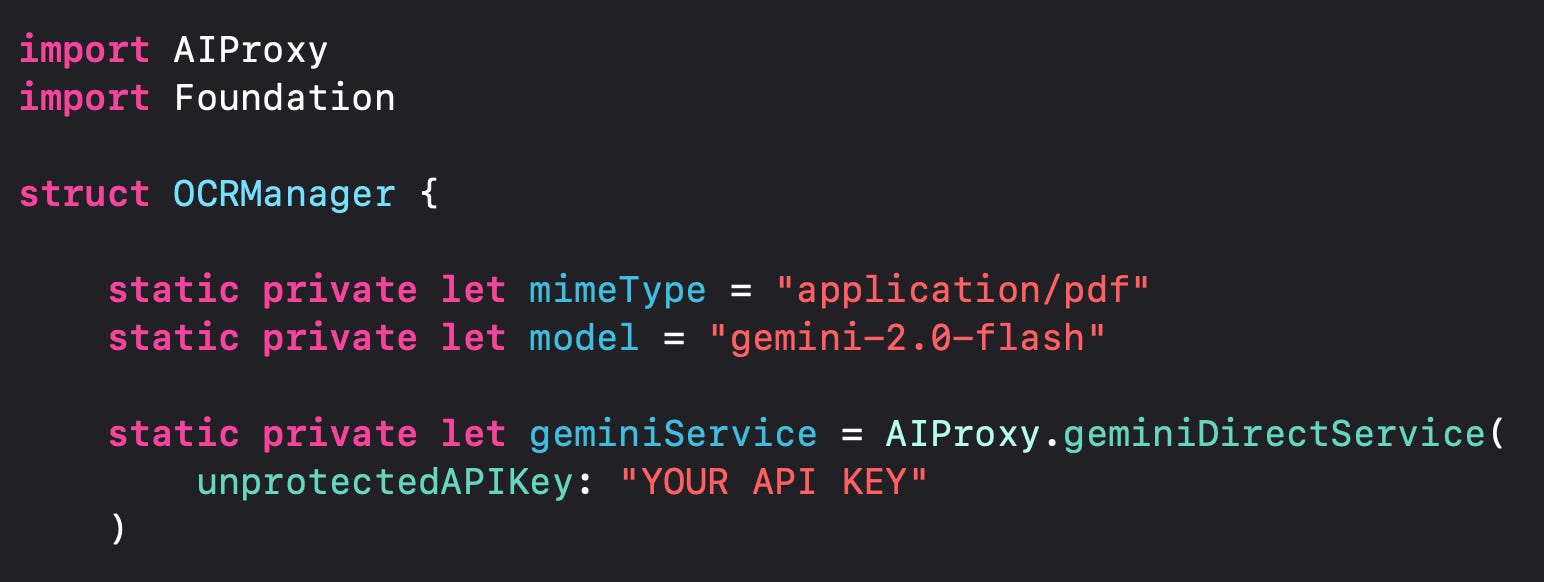
To work with PDF documents in Gemini, the first step is to upload your document. Using the AIProxySwift library makes this process straightforward.
Begin by setting up the Gemini service with your API key:
Now just upload the document data:
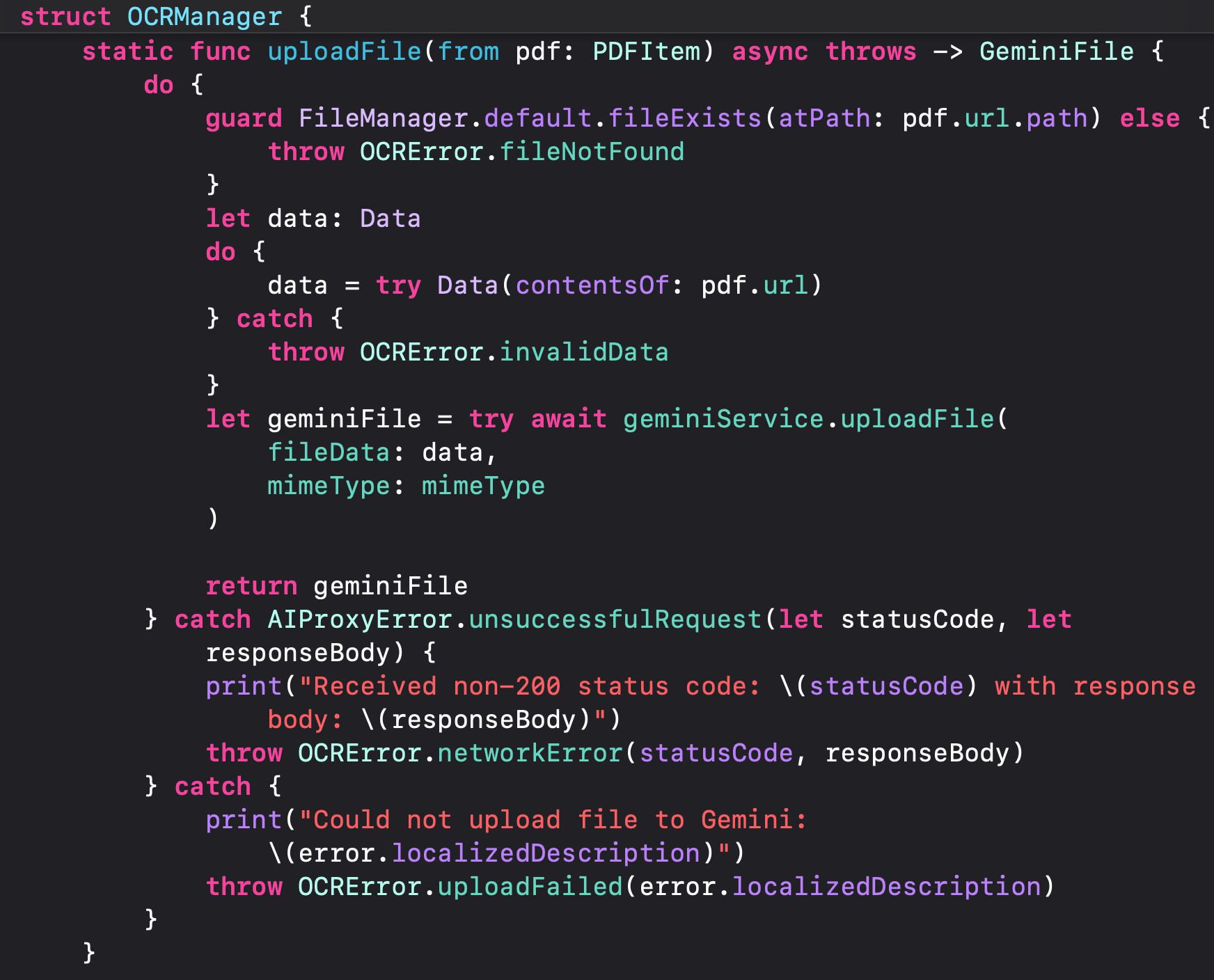
You will receive back a `GeminiFile` object, which includes the file `uri` (ID) to reference this document further.
Next, prompt the Gemini model to return the document in your desired text format. For my use case, I chose HTML because it’s easy to display in a Swift app and preserves the original formatting. I also configured the model to chunk the document by wrapping each section in <chunk></chunk> tags, making it simple to parse later. I used the following prompt:
static private let ocrPlusChunkingPrompt = """
OCR the following page into semantic HTML. Use appropriate HTML5 tags for semantic structure:
Use appropriate HTML5 tags for semantic structure:
- Use <h1> for main titles/headings
- Use <h2>, <h3> etc for section headings in order of importance
- Use <strong> for bold text
- Use <em> for italics/emphasis
- Use <ul> and <li> for unordered lists
- Use <ol> and <li> for ordered/numbered lists
- Use <table>, <tr>, <th>, <td> for tabular data
- Use <p> for paragraphs
- Use <a href="..."> for links
- Use <section> to group related content
- Use <article> for self-contained content
- Use <header> and <footer> where appropriate
- Use <nav> for navigation sections
- Use <time> for dates and timestamps
- Use <address> for contact information
- Use <figure> and <figcaption> for images and captions
- Use <blockquote> for quoted content
- Use <dl>, <dt>, <dd> for definition lists
Format with proper indentation and line breaks for readability.
Chunk the document into semantically coherent sections of roughly 250-1000 words. Each chunk should contain complete, related content on a single theme or topic (e.g., contact info, work experience, education, etc).
Surround each chunk with <chunk> </chunk> tags. Preserve all HTML formatting within the chunks.
Example chunk structure:
<chunk>
<section class="contact">
<h2>Contact Information</h2>
<address>
<p>Email: example@email.com</p>
<p>Phone: (555) 555-5555</p>
</address>
</section>
</chunk>
"""Then a regular `generateContentRequest` is passed to the gemini service referencing the pdf file uri:
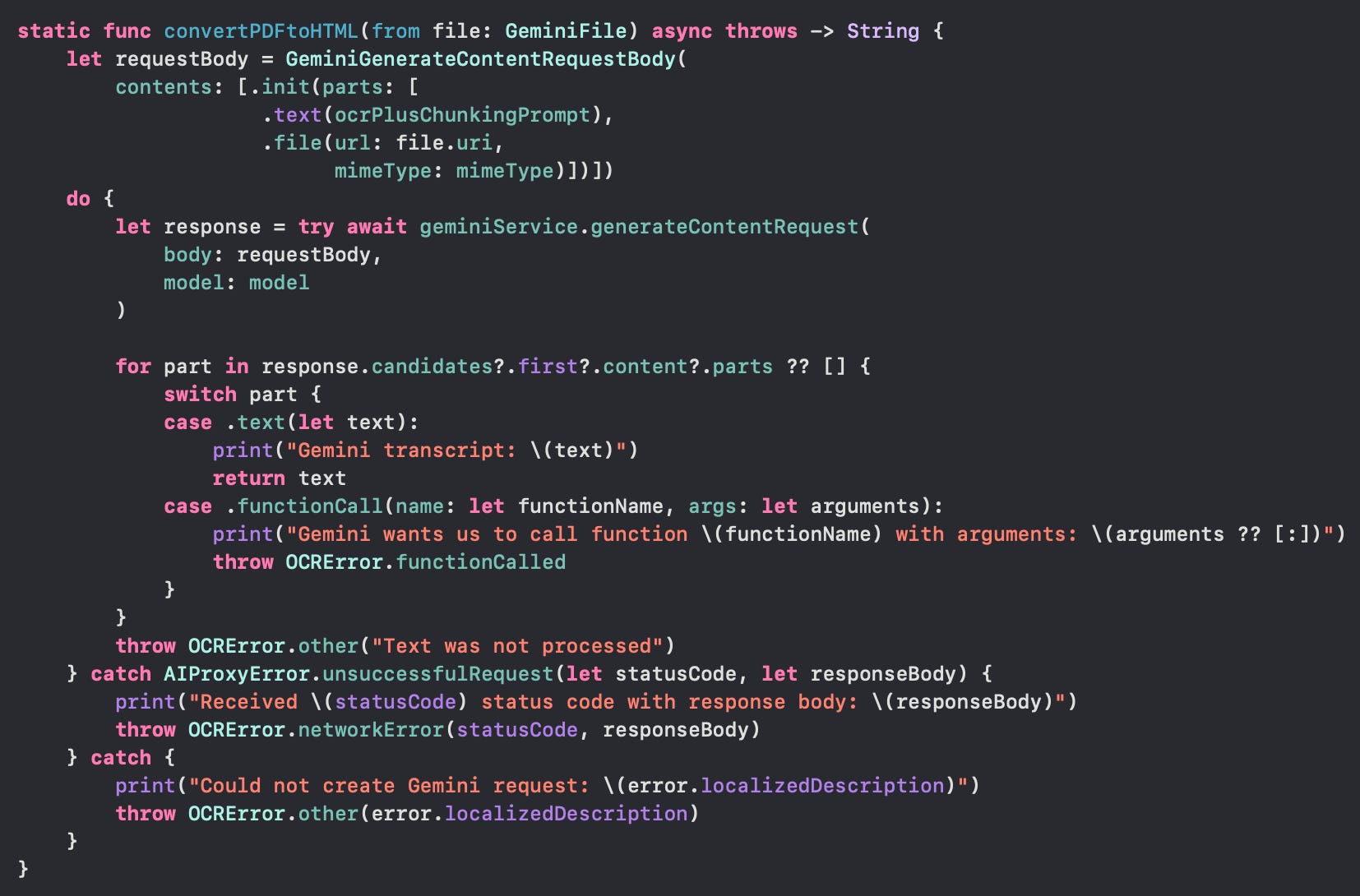
The text is then split into chunks and processed into PDFChunk objects.
Analyzing each Chunk
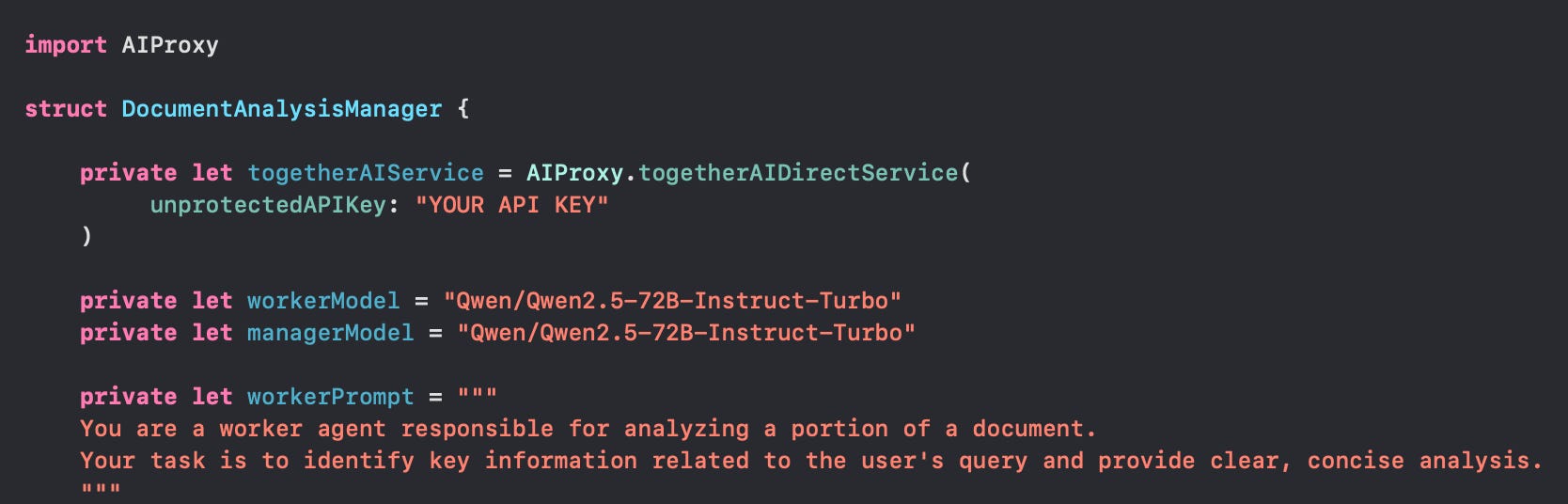
Once the user submits a query about the PDF, the “Worker Model” will check each chunk for any information relevant to the query. In my case, I wanted to use the meta-llama/Llama-3.3-70B-Instruct-Turbo-Free model from TogetherAI as Rudrank Riyam did in his implementation of Chain-of-Agents implementation, which is completely free. However, I found the model to be super rate-limited. So I changed to using the Qwen/Qwen2.5-72B-Instruct-Turbo, which costs only $0.90 / 1 million tokens.
The setup using AIProxy was is as follows:
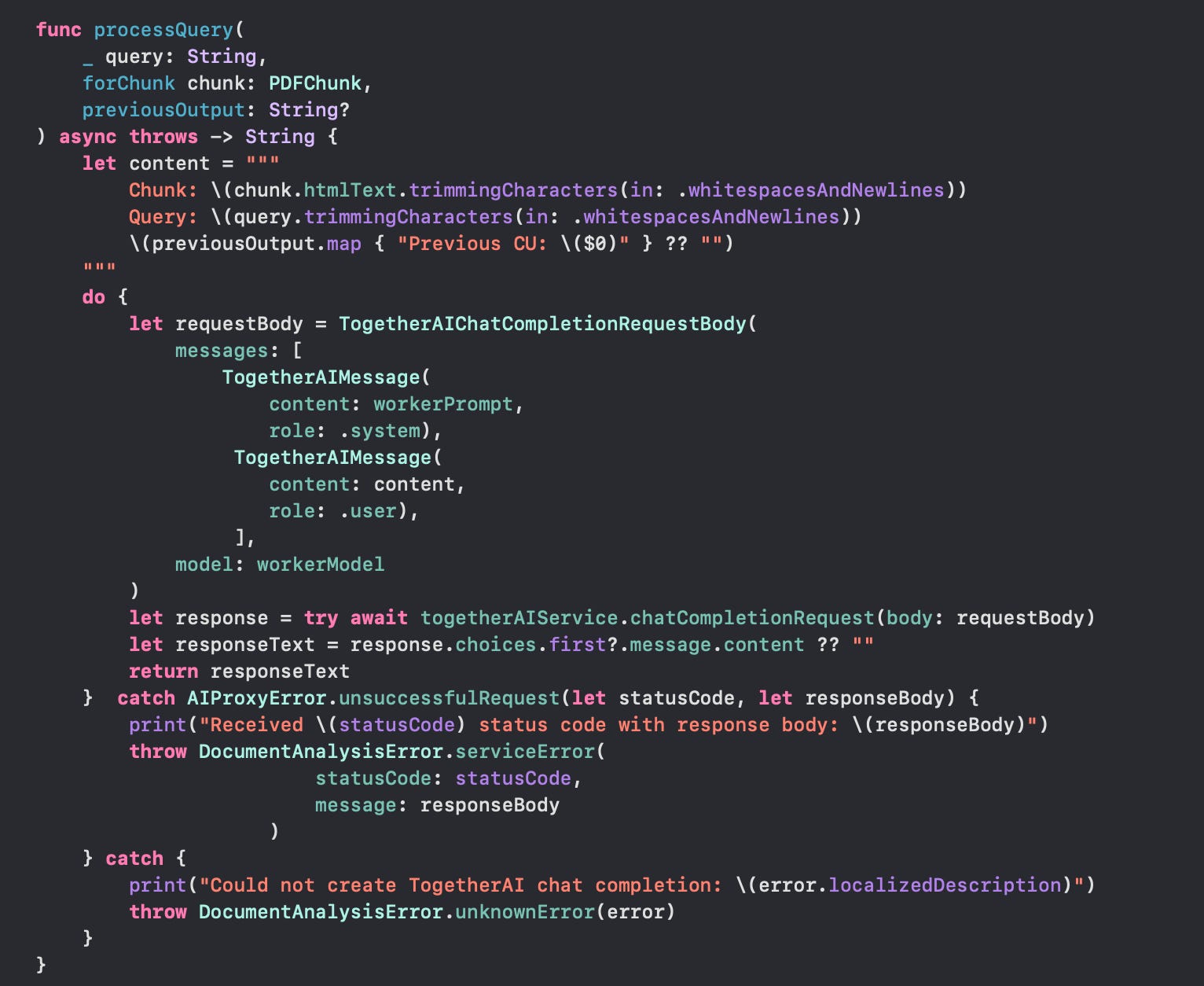
Then it’s just a matter of passing in the user’s query, the pdf chunk to process, and the previous model’s output (Cognitive Unit) if any:
To call this method from the UI or a ViewModel requires keeping track of all the worker outputs:
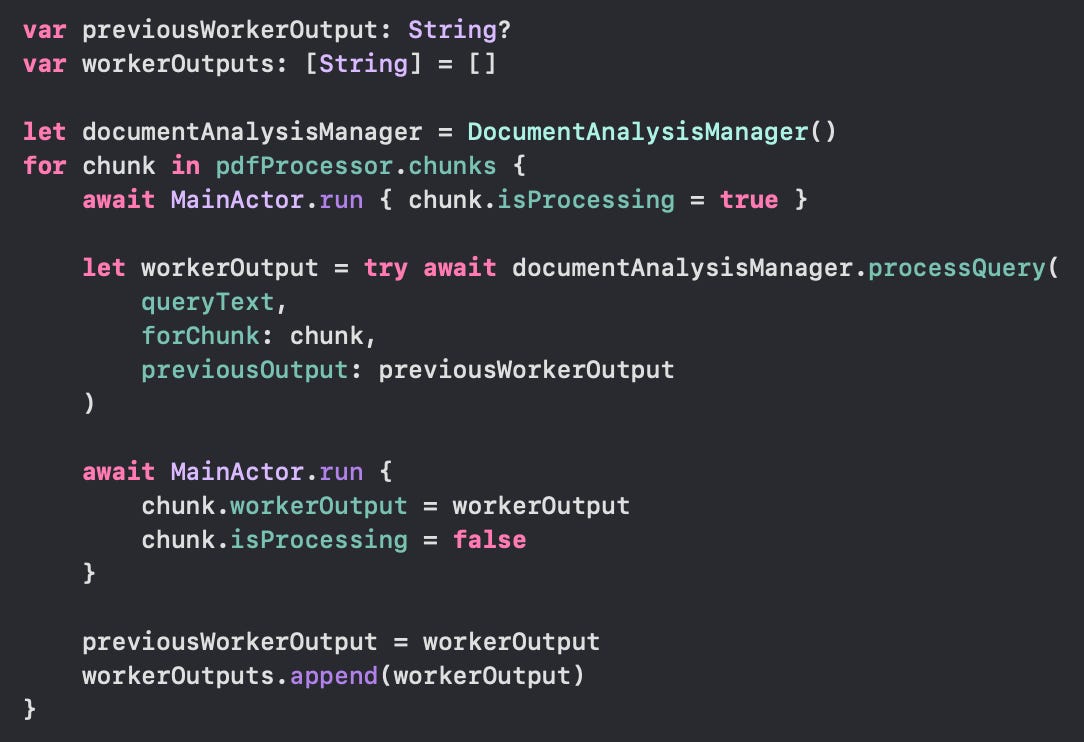
Once all the chunks are analyzed, we can pass all the worker outputs to the Manager Model to synthesize the answer to the user.
Synthesizing the Answer
For the Manager Model, I selected the Qwen/Qwen2.5-72B-Instruct-Turbo model—identical to the one used for the Worker Model. However, the optimal choice depends on your app’s unique requirements, so experimenting with different models is key to achieving the best synthesized response. In some cases, using distinct models for the Worker and Manager roles might be beneficial. For instance, you might explore a reasoning model like DeepSeek R1 for analyzing complex queries in the chunks.
After some experimentation, my final Manager Model prompt was as follows:
private let managerPrompt = """
You are a senior analyst providing precise answers to queries.
Your response must:
1. State only the directly relevant information
2. Exclude any mentions of where or how the information was found
3. Omit any references to document sections, analysis methods, or supplementary context
4. Present information as a simple, factual statement
5. Remove any meta-commentary about the information's location or completeness
Example:
Query: "What is the candidate's phone number?"
✓ Good: "The candidate's phone number is 310-708-5552."
✗ Bad: "The candidate's phone number is 310-708-5552, which was found in the contact section, though it is not present in several other sections that focus on the candidate's professional experience, skills, and educational background."
Always write concise, direct responses without any additional context or commentary.
"""The worker outputs were then combined and sent to the model along with the user’s query:
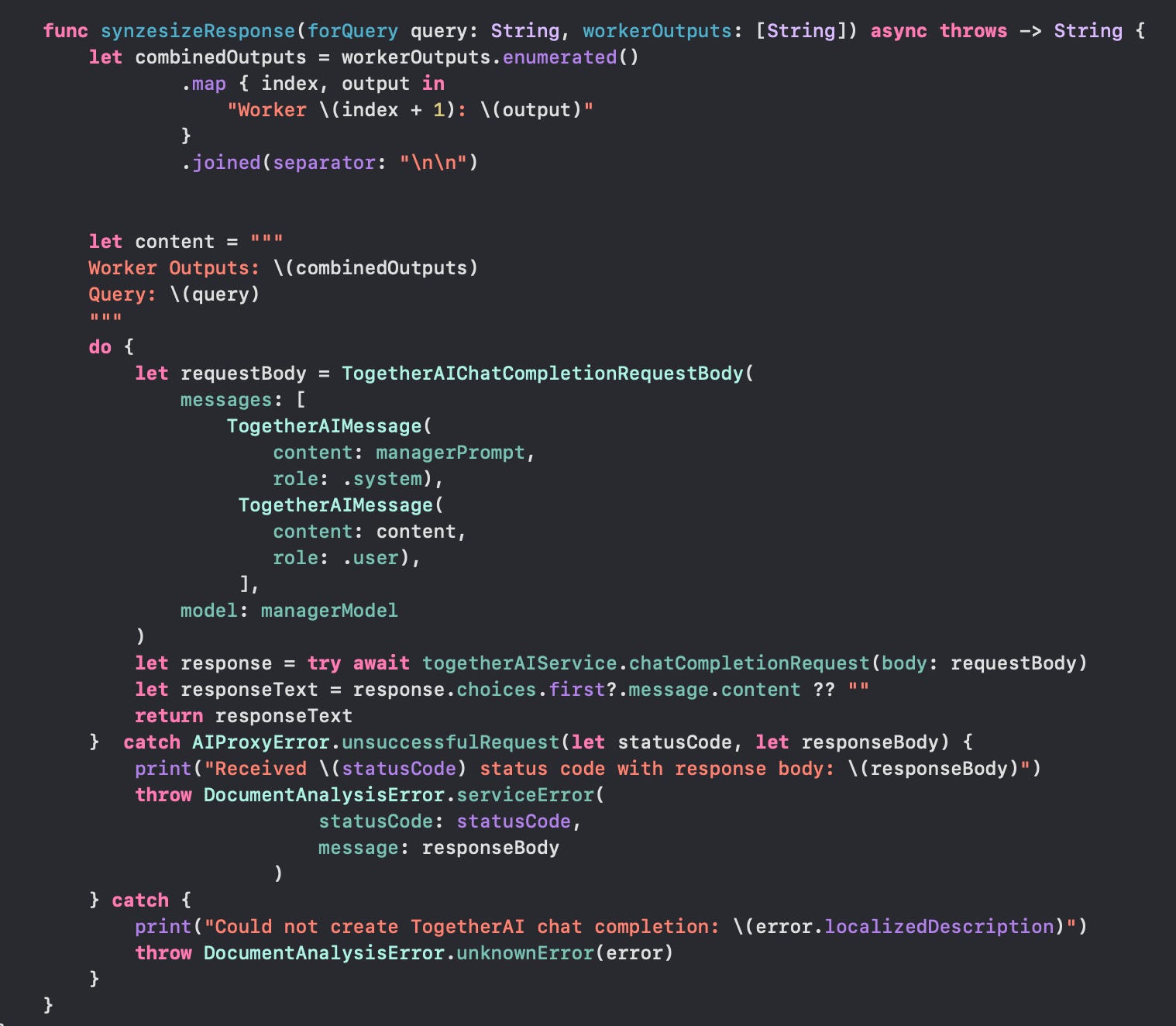
The full response was displayed in the UI after all the chunks were analyzed:
And that’s it—a complete workflow that takes you from breaking down a document into manageable, context-aware chunks to delivering a clear, concise answer to your query.
And as always, the complete project code is available exclusively to paid subscribers.
Happy coding!