
The Art of AI Reasoning: How to Think about Thinking Models
Explore the inner workings of reasoning models in comparison to standard chat models, and learn practical best practices for effectively combining and prompting these models to tackle multi-step tasks

Yesterday, OpenAI published a comprehensive guide outlining best practices for working with reasoning models. I wanted to provide some interesting key insights that stood out to me as a developer, but first it’s important to understand the background of reasoning models.
How LLMs are Trained
Constructing a Smart Auto-Completion System
The initial training of a Large Language Model (LLM) involves several key steps:
Data Collection: The process begins with gathering a vast array of documents from the internet. This involves web scraping across countless websites to compile a diverse dataset that captures a wide range of language patterns and contexts.
Data Preparation: Once collected, these documents are preprocessed and segmented into smaller text snippets. These snippets serve as the training data for the model.
Learning Through Prediction: The core training task requires the model to predict the next token (a word or part of a word) in a given sequence. Initially, the model’s predictions are inaccurate. However, as it processes more examples, it continuously adjusts its internal parameters through techniques like backpropagation. Over time, the algorithm is fine-tuned to increasingly predict the most likely next token.
Creating an Auto-Completion Engine: The outcome of this training is essentially a sophisticated auto-completion system. When you provide the model with an input text, it predicts the next token, appends it to the input, and uses the extended sequence to predict the subsequent token. This process repeats, allowing the model to generate coherent and contextually relevant text one token at a time.
Enforcing Chat Structure with Human Input
The next step, often referred to as post-training or reinforcement learning with human supervision, involves engaging human annotators to craft realistic User/Assistant dialogues. These conversation transcripts are then used to fine-tune the model, training it to generate responses that fit seamlessly within this dialogue format.
Note that both user and assistant exchanges are merged into a single, continuous text block. The model treats this entire block as one piece of input and simply auto-completes it to continue the conversation.
For visualizing this process, I highly recommend watching Large Language Models explained briefly by 3Blue1Brown:
Post Training: Reinforcement Learning
I recently watched Andrej Karpathy’s new video: Deep Dive into LLMs like ChatGPT. It is 3.5 hours long and totally worth it!
In the video, I learned about a potential third stage of LLM training—Reinforcement Learning. In this phase, the model is provided with a set of problems and their correct answers, but it has the freedom to devise its own solutions. Incorrect approaches are deprioritized, while strategies that successfully yield the right answers are reinforced and optimized.
This is a great diagram of this process from the video for visualization.
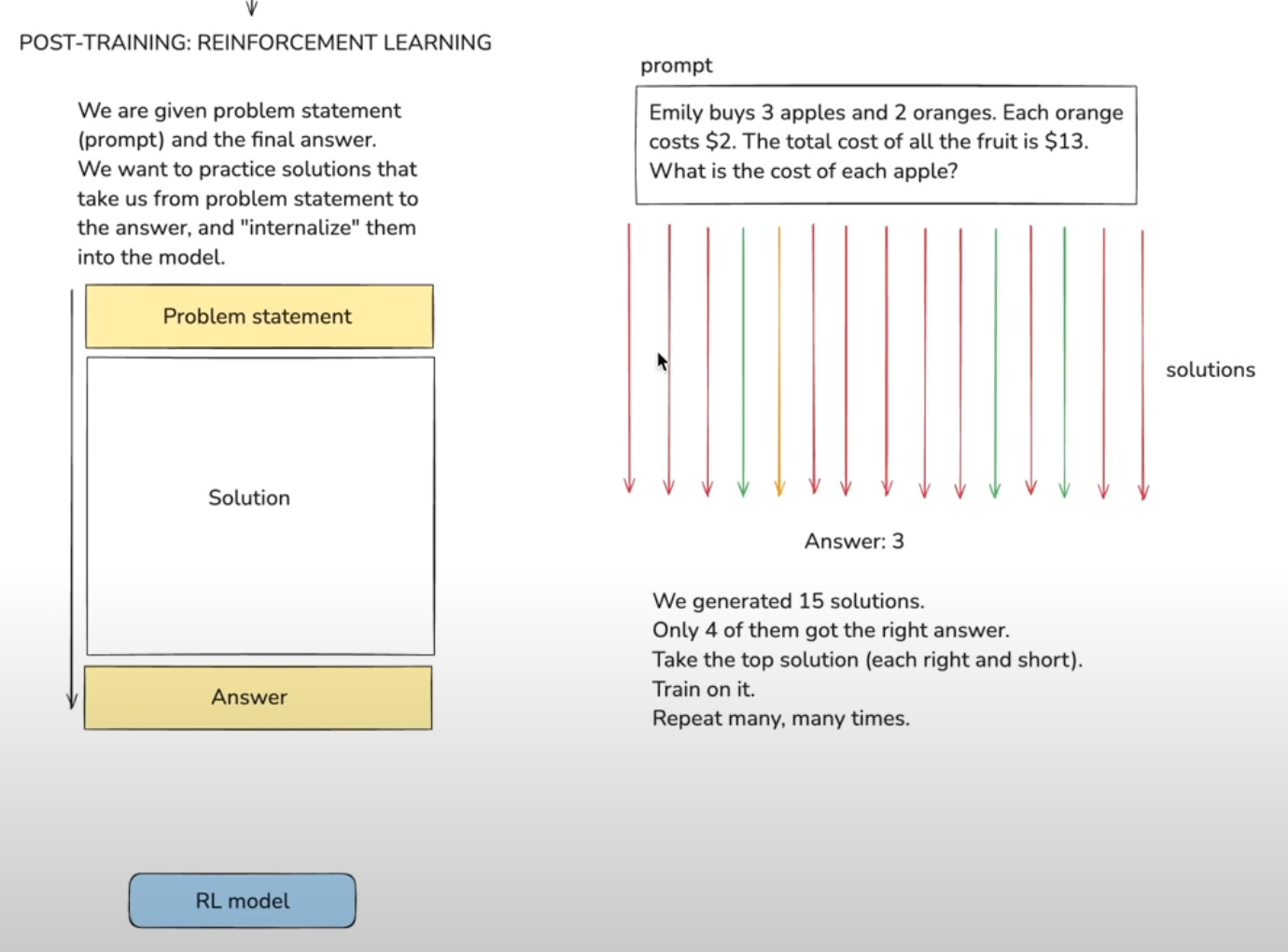
It’s important to note that this process is specifically for problems with definitive, verifiable answers—such as mathematical equations, scientific computations, and code generation.
Now let’s go back to the fact that the model is completely free to do whatever it takes on it’s own to arrive at the correct answer. The is where things get interesting. After analyzing the solutions that worked best to solve these harder problems, researchers found that the model will generate “thinking” tokens before coming up with the final answer.
While OpenAI keeps these “thinking” tokens hidden, the new open source DeepSeek R1 model—performing on par with OpenAI’s o1—actually shows them off, and the result is pretty entertaining.
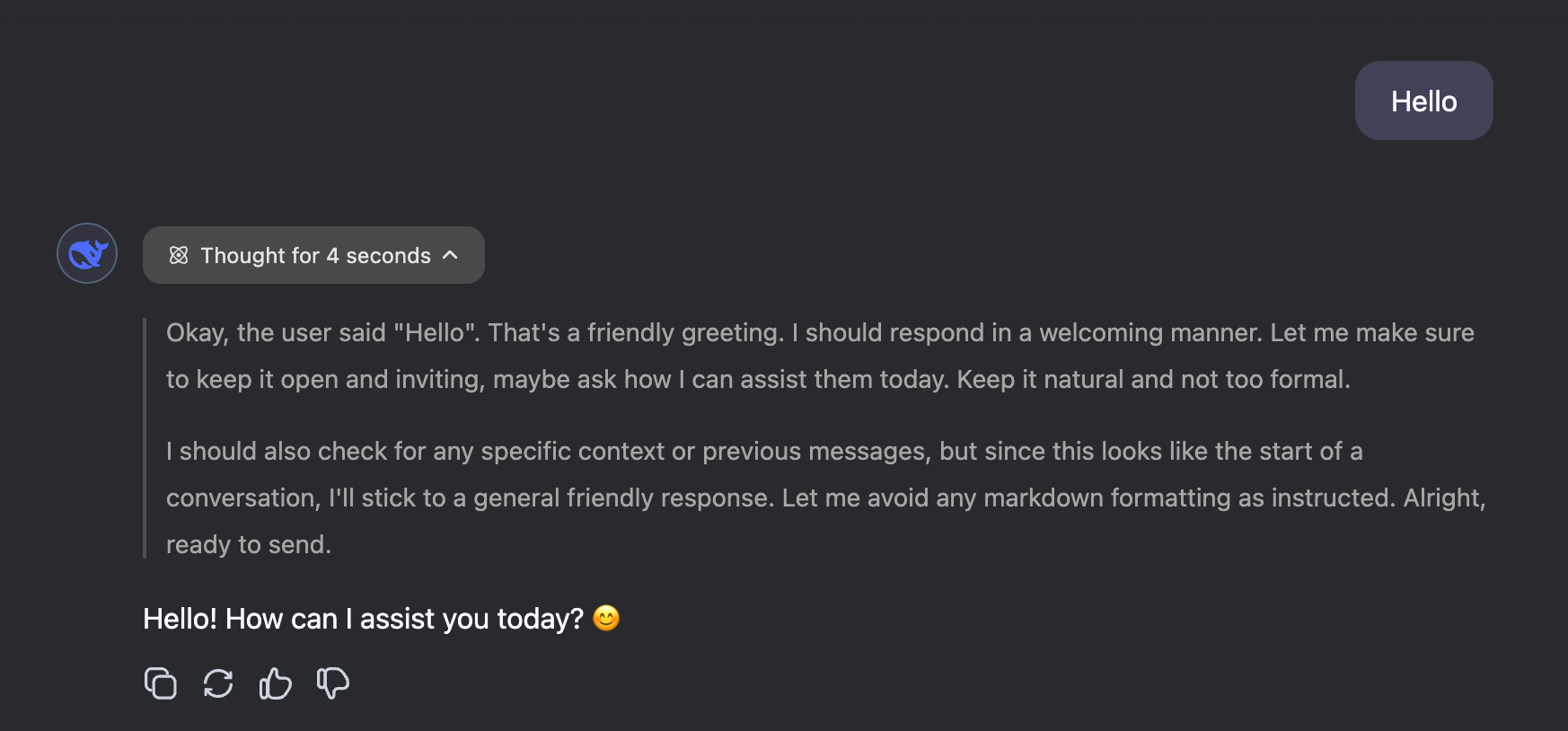
It’s hard not to see a bit of personality in this model—it comes off like an insecure teenager, pausing and mulling things over before finally delivering an answer. But don’t be fooled—it’s still just an auto-complete model. It simply uses extra tokens to add more context to the prompt, which in turn leads to more accurate responses. Recognizing this is key to understanding how to work with these reasoning models.
When to use Reasoning Models
While reasoning models can excel at complex tasks, they come with a couple of notable downsides:
Higher Costs: They generate extra tokens, which means more context and more expense.
Slow Response Times: More tokens also mean they take longer to produce an answer. Sometimes thinking for as long as 5 minutes or even more!
Going back to the fact that reasoning models work by adding “thinking” or extra context to the prompt, it is worth experimenting with simply improving the details / context of a prompt that is sent to a cheaper non-reasoning model to achieve similar results. You can also add instructions to “think step-by-step” to a non-reasoning model.
However, there are times when a reasoning model can solve problems that a non-reasoning model just can’t crack. As OpenAI’s guide explains:
We trained our o-series models (“the planners”) to think longer and harder about complex tasks, making them effective at strategizing, planning solutions to complex problems, and making decisions based on large volumes of ambiguous information. These models can also execute tasks with high accuracy and precision, making them ideal for domains that would otherwise require a human expert—like math, science, engineering, financial services, and legal services.
So what OpenAI suggests is very interesting - combine the use of reasoning models with the straightforward non-reasoning models. Using only the o-1 series models when extremely necessary - to make a step-by-step clear plan for the solution with specific tasks. Than use the non-reasoning models as “workhorses” to complete the straightforward well-defined tasks.
Prompting Reasoning Models
Make sure to avoid “boomer prompts” with reasoning models 🤣
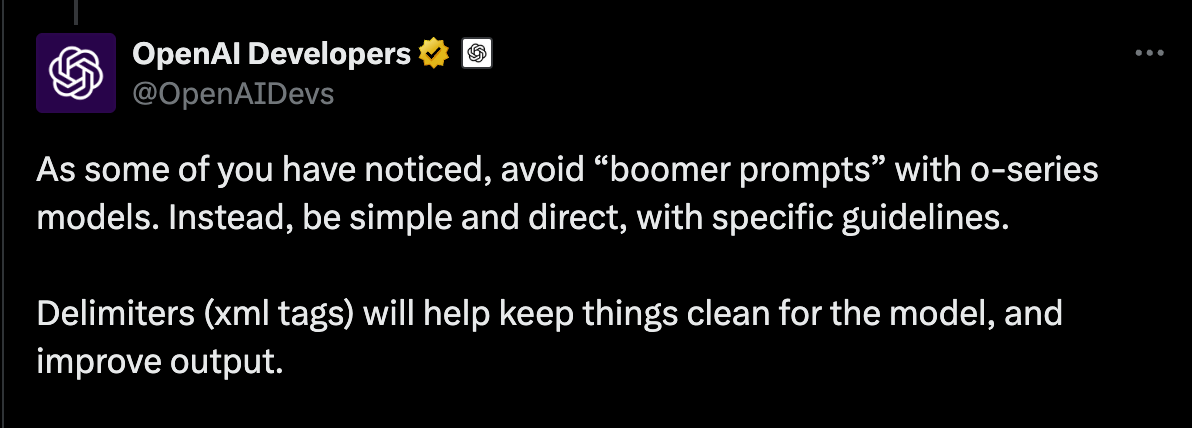
You can read the full prompting guidelines in the OpenAI blog post. Here are the key takeaways:
As outlined in their training process, these reasoning models are given both the problem and the answer, and their job is to work through the solution—no matter how many tokens it takes. So to make the best use of these models, it’s crucial to be very specific about the your end goal when crafting your prompt:
Be very specific about your end goal: In your instructions, try to give very specific parameters for a successful response, and encourage the model to keep reasoning and iterating until it matches your success criteria.
Secondly, while Anthropic has been very clear about the importance of using XML tags with their models, OpenAI hasn’t been as explicit—until now. OpenAI does point out that using XML, markdown, and section titles can help break down your prompt into clear, distinct parts. They state:
Use delimiters for clarity: Use delimiters like markdown, XML tags, and section titles to clearly indicate distinct parts of the input, helping the model interpret different sections appropriately.
Conclusion
Reasoning models offer a powerful edge for tackling complex, ambiguous tasks that demand careful planning and high accuracy—even if they come with higher costs and longer response times. By understanding their training process and behavior, you can smartly mix these “planners” with your regular, more cost-efficient GPT models to get the best of both worlds.
Whether you’re navigating intricate documents, extracting key insights, or orchestrating multi-step workflows, the key is to craft your prompts with clear, specific goals and structured context. As these techniques continue to evolve, they open up exciting opportunities for building smarter, more adaptable AI-powered Swift apps that haven’t been possible before 🚀