
Introduction to Apple's FoundationModels: Limitations, Capabilities, Tools
Learn how to get started with Apple's FoundationModels Framework

I was finally able to upgrade to macOS Tahoe, and now I’m excited to experiment with Apple’s new FoundationModels!! I’m going to start out by watching the WWDC25 videos about these models, experimenting with them, and writing about them here for later reference. Note that these will be introductory posts based on the videos and documentation for now, but will get more advanced as I get to experiment and learn and build in time to release a few apps I have in mind for September.
This blog post is focused on the Meet the Foundation Models framework video:
Limitations
While extremely impressive and a dream-come-true for many Apple Developers - an on-device FREE PRIVATE model!! - it’s important to keep in mind that the model is highly limited.
First - it is small enough to fit on device. A big PRO! But the CON is that the model will just not be as powerful as LLMs provided by OpenAI, Google, or Anthropic. Expect it to not “know” as much as users are used to from larger LLMs, to hallucinate, and have severe logic limitations. This model will not “think” or do a web search or run quick code in a Python interpreter to verify information as the new OpenAI / Google / Anthropic agentic models do.
Instead, focus on it’s strengths - processing natural language. As mentioned in the video, the FoundationModel should be used for the following simple tasks with text:
Summarization
Extraction
Classification
Tagging
Composition
Revision
Again - all of these tasks are focused around processing existing simple language. Read more about the FoundationModel training data here.
Training Cut-off Date
As already mentioned, I wouldn’t rely on this model too much for important factual information - unless it is summarizing the information that I explicitly give it. But this is especially true for the most up-to-date information.
I don’t think we have a model training cut-off date, but many of these models have been trained over a year ago! And the more time passes, the more irrelevant the recent events data becomes. Here is what happens when I ask for today’s date:

And just to confirm the training cut-off, here is what we get if ask who the current U.S. President is:

Looks like the training cut-off is October 2023…
Limited Context Window
The FoundationModel is limited to only 4096 tokens - both input AND output!! This is approximately 3,000 words… So don’t count on summarizing long text / PDFs… or even building a long chat. Keep it short and simple!
Limited Language Support
It’s hard to find information about which languages are supported by the Foundation Model, but there is a small footnote in the Apple supercharges its tools and technologies for developers to foster creativity, innovation, and design press release that mentions the same languages as supported by Apple Intelligence:
English
French
German
Italian
Portuguese (Brazil)
Spanish
Japanese
Korean
Chinese (simplified)
With more languages coming “by the end of this year”: Danish, Dutch, Norwegian, Portuguese (Portugal), Swedish, Turkish, Chinese (traditional), and Vietnamese. Not even Hindi :(
Text-Only Input
Many of us (and our users) are now take multimodal models for granted - we’re used to being able to input audio, video, images, PDFs, etc and get a very nice impressive response. However, with the FoundationModels framework, we need to take a step back. Back to LLM capabilities only. Only text input works as of now.
Safety and Guardrails
The FoundationModel is extremely guardrailed:
First, the framework uses an on-device language model that’s trained to handle sensitive topics with care. Second, the framework uses guardrails that Apple developed with a responsible AI approach. These guardrails flag sensitive content, such as self-harm, violence, and adult sexual material, from model input and output.
While this is good on the surface of how language models should behave, in practice this creates a lot of false positives, which is pointed out in the documentation:

Again - you will have to really test the prompts to make sure the app’s guardrails will not be activated unexpectedly.
Unknown Updates
It seems like Apple plans to update the FoundationModels framework before next year (probably several times). And we, as developers, have no idea when it will happen and how it will impact our existing apps. After all - Apple cannot test that the new model will not break our current specific app use-case. And there doesn’t seem to be a way to refer to a specific release of the model.
Availability
The first issue with using FoundationModels is understanding their availability and therefore including a fallback experience for users who do not have these available. According to Apple’s documentation:

The Apple Intelligence webpage lists the following devices as compatible:

And of course, users must have iOS 26+, macOS 26+, and visionOS 26+ installed on their compatible device.
The code for checking availability and displaying error messages in your view is as follows:

Note that there are currently three reasons for the model being unavailable:
The device is not eligible (see above for eligible devices from the Apple Intelligence website)
Apple Intelligence is not enabled - this is a simple fix for the user if they want the extra features.
Model not ready
Since this framework is in beta and will for sure change in the future, it’s also important to include an unknown default reason that may be added in future versions.
Now onto the fun part!
Hello World
To quickly play around with the model, we can now quickly add the #Playground macro to any Swift file and see the results right away! Simply import the Playgrounds framework and start testing out different prompts.
Getting started with the FoundationModels takes only three simple steps:
Import the FoundationModels framework
Create a
LanguageModelSessionPass it a prompt!
That’s it! Only a few simple lines of code:

Instructions
Now, if you’ve used other LLMs, we know that we need to first give the model a system prompt - called instructions in the FoundationModels language. This is done when setting up the LanguageModelSession initially:

One thing I really liked from the video was how they broke down the difference between Instructions vs Prompts:
Instructions should only come from you, the developer / app
Prompts can come from you or the user!
In other words, you should never allow the user access to modify the models instructions.
Iteration
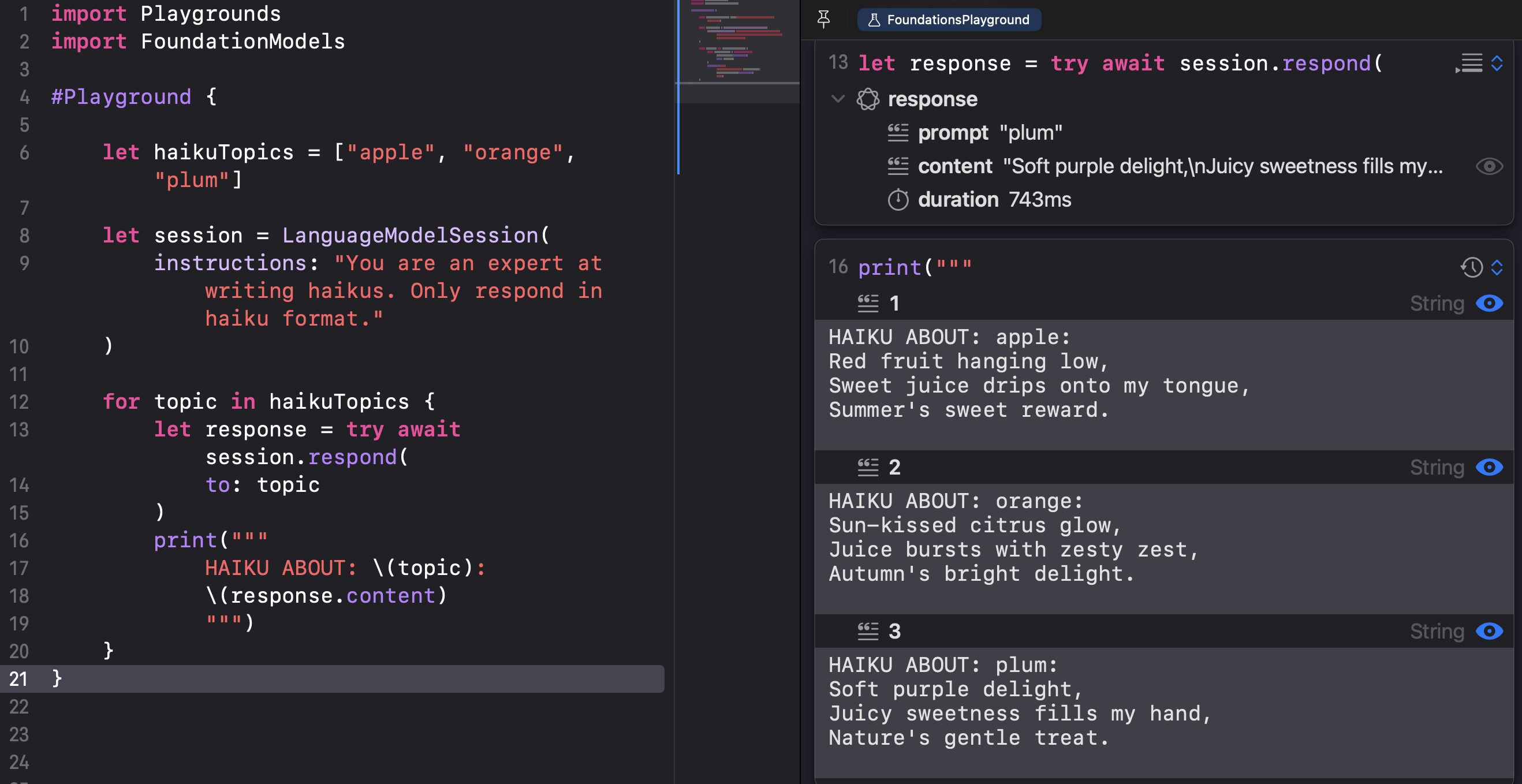
If you have an array of items for the model to respond to, you can simply iterate over your array of items and get a list of responses from the model:
Saved Conversation History
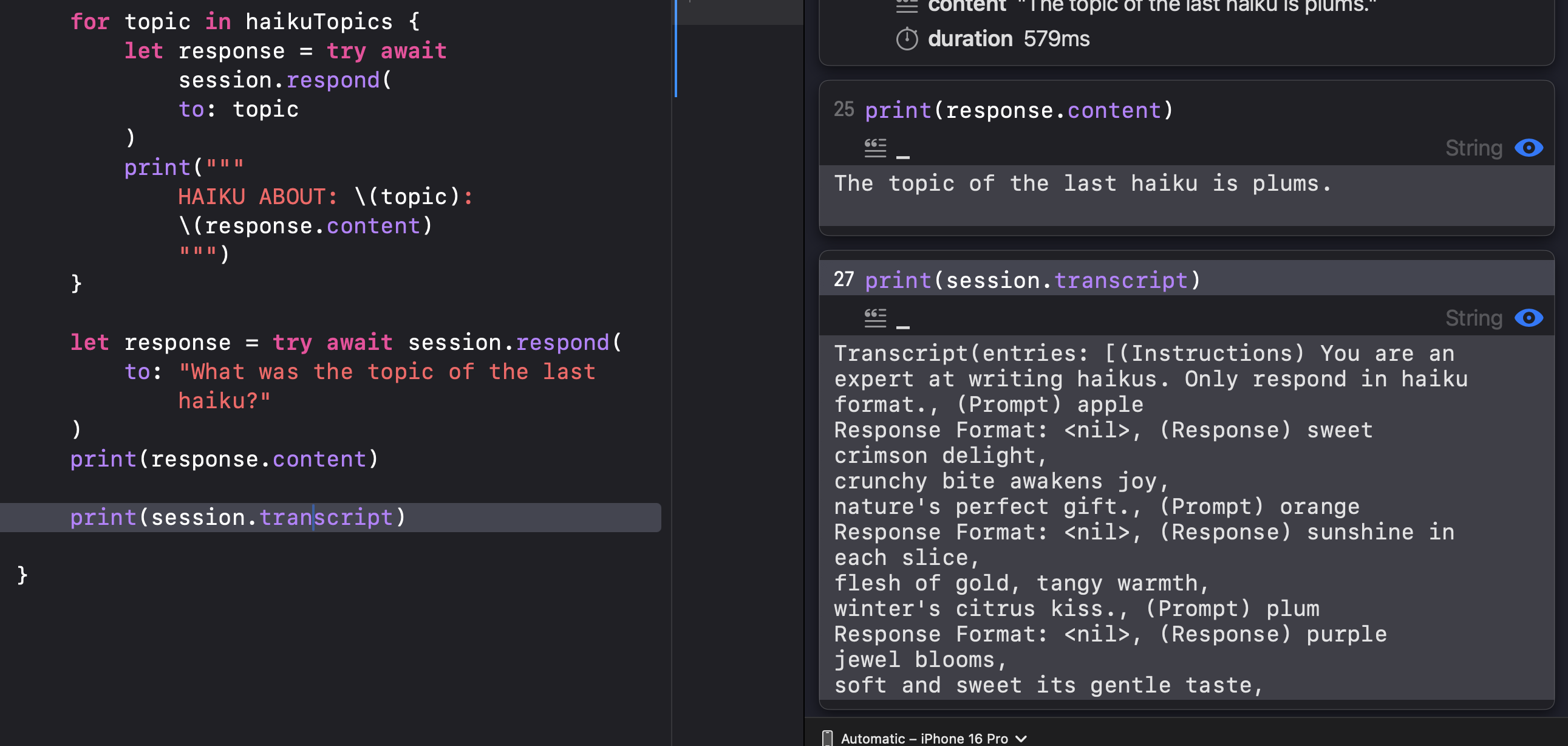
This is something that I really love about the FoundationModels API - the message history is automatically saved by the LanguageModelSession for you! If you’ve used other LLM APIs, you’d know that you usually have to send the full message history to the model every single time you need a response!
So when I ask the model for this session about the topic of the last haiku, it knows automatically!

Funny enough, the model DID NOT follow the initial instructions to respond only in haiku format when asked about the topic of the last haiku. And one time it printed out the topic of the last haiku as orange instead of plum… So it is super important to test out these multi-turn interactions to make sure the user interactions stay on track and do not hallucinate the important information, especially when the user provides the prompt :)
Full Transcript
And if you do need a full transcript (maybe you need to send the full conversation history to an larger server-side API after all!), it is very easily available in the session object:
Generable - NO JSON!!! NO CODABLE!!!
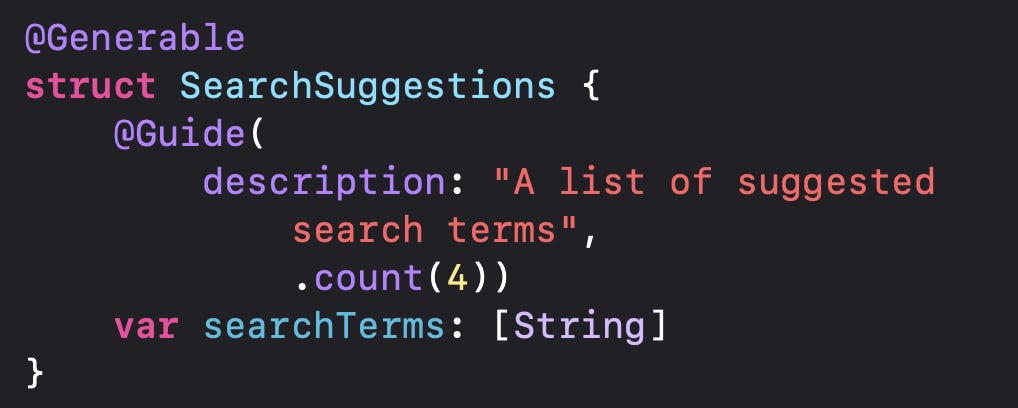
Now onto the super impressive things!!! The FoundationModels has introduced a @Generable macro, which will automatically turn the FoundationModels responses to a typed Swift object, without any JSON / Codable!!
It’s as simple as this:
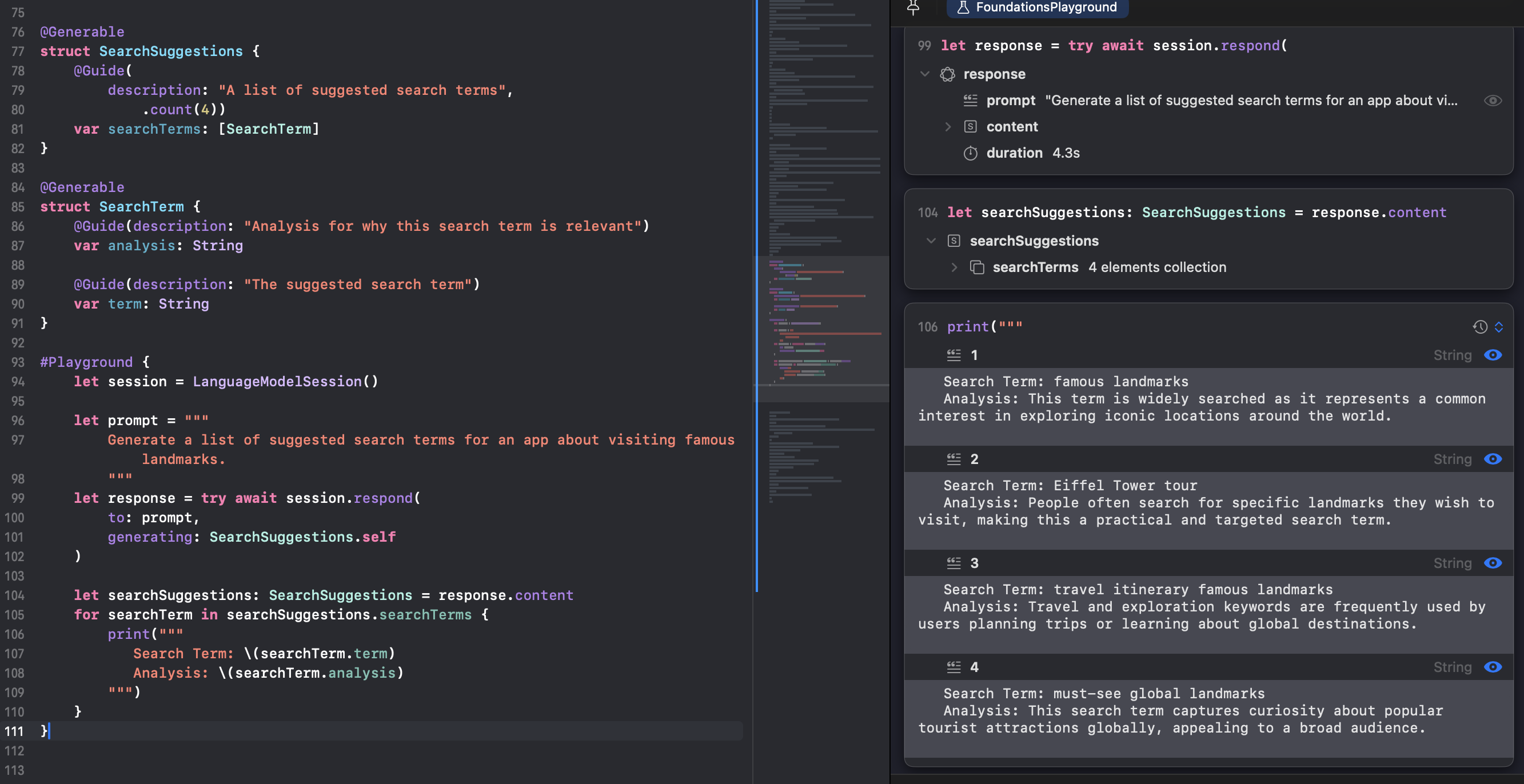
Now just use this object as a generating item along with the prompt:

Notice how the response.content object is automatically typed to the @Generable SearchSuggestions object!
Property Ordering
LLMs generate content one token (*sub-word*) at a time. This means that if you want the LLM to “reason” or “think” you can first add a longer-form property such as “analysis” first then the main smaller-form property after.
For example, we can create a SearchTerm object which has the analysis of why this search term is relevant first, and the actual term later. For the user, we will only show the term, but by putting “analysis” as the first property, we’re giving the model more tokens to “think” through before coming up with a compelling suggestion:
Generable Composition
In the last example, you may have noticed something super cool! The Foundation Model is able to generate ALL nested Generable objects!
Check out this TravelItinerary object with an array of Generable Destination objects with an array of Generable Activity objects!

It’s able to generate all the objects!

Again - note that travel is not a great use-case for this model as it may hallucinate travel information or provide old information that is not up-to-date. So just use this as an example of object composition…
Tools
As we discussed in the Limitations section, one of the issues with the Foundation Model is that it has a cutoff date maybe around October 2023, so it doesn’t have access to the most recent information, including today’s date!
But it’s not a big deal. We can give it the Tools it needs to get the relevant information to our app. Here is a simple GetCurrentDateTool:

To use it - we simply include the tool in the LanguageModelSession:

Notice that you can pass in multiple tools to the model - this is especially useful on iPhone as you can give access to the user’s Calendar, Reminders, Location, and much more personalized data from your app without risking the user’s privacy!
The model will figure out when to call each tool based on the context of the conversation! And you don’t even have to manage the back and forth of getting the tool response and sending it back to the model - this is done automatically for you!!! The Foundation Model API is truly impressive!
Conclusion
I wanted to include a few more things, but this post is already long enough, so I’ll continue on tomorrow with extra features of the FoundationModels framework as I continue to learn and figure out how to integrate it into apps.
I know I mentioned a lot of limitations in the beginning of this blog post, so I wanted to end here with a more positive view. We have an incredibly powerful natural language processing model ON DEVICE for FREE!! And the capabilities are on par and probably better than most MLX on-device models. So this is truly a big WIN for us as Apple developers, and I’m excited to see Apple continue on this path of providing more options and capabilities for us to work with in a beautiful Swift API :)
Happy Building!
Great introduction! One thing to note on macOS 26 is that if you upgrade from Sonoma to Tahoe, you might run out of space. You can reinstall in Settings-> General-> Transfer or reset. The Base Tahoe installation
with Xcode 26 is about 120 GB and works pretty well if you have your Apple ID and info backed up to iCloud. For my next Mac purchase, I will start with 2Gb. I have heard you can set up a Tahoe VM, but have not tried it yet.
Excellent article Natasha, thanks!
A few notes from things I learned in WWDC25 labs relevant to what you wrote:
- Engineers said we can expect the models to be updated with each new version of the OS. They also said we should have time during beta of those OS to test for regressions, and especially have time to update our adapters.
However during beta 1, something contradictory happened: users of 26 beta 1 (all platforms) got an update directly in Apple Intelligence settings.
Which means that supposedly they are also capable of updating it without pushing a new OS version.
- Compared to MLX, performance should be better indeed. Foundation Models run on the neural engine, (and I assume it can also mobilize CPU and GPU), whereas MLX models can only run currently on CPU + GPU. That should give a nice performance boost.