
Balancing Creativity and Consistency: How Temperature Shapes LLM Responses
Explore how temperature influences the behavior of Large Language Models (LLMs) - control the balance between creative, diverse outputs and consistent, reliable responses

If you’ve ever used apps or APIs like ChatGPT, Claude, or DeepSeek, it might seem like there’s just one ‘perfect’ answer generated for your query. However, Large Language Models (LLMs) don’t work in such a deterministic way.
Important Background: How LLMs Work
Instead, they generate outputs by predicting the next word—or more precisely, tokens, which are fragments of words—with varying probabilities. Once the next word (token) is predicted, the initial input + the next selected generated word (token) are input back into the model to predict the next word (token) and so on until the full answer is generated.
Watch this amazing video by 3Blue1Brown to visualize this process:
This means there are multiple possible paths the model could take to construct a response, influenced by factors like randomness and probability weighting.
What is Temperature?
As shown in the video, an LLM generates a list of possible next words (tokens), each with an associated probability:
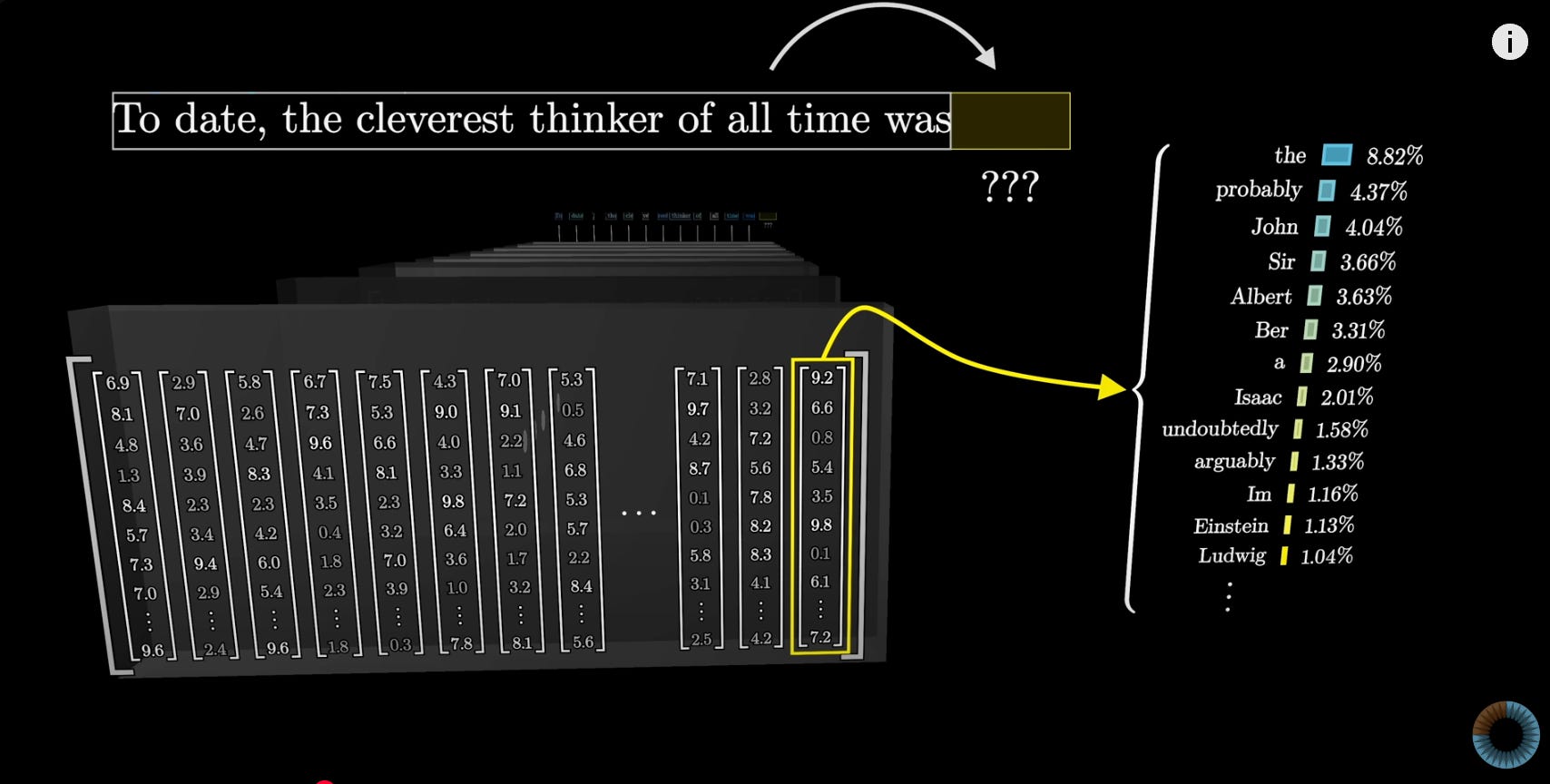
While it might seem logical to always select the word with the highest probability, doing so leads to repetitive and overly deterministic responses. This approach strips creativity and nuance from the output, making it less engaging and less human-like.
This is where temperature comes into play. As developers, we can adjust this parameter to control how deterministic or random a response should be. A lower temperature encourages the model to choose higher-probability words, resulting in more consistent but predictable responses. Conversely, a higher temperature introduces more randomness, allowing the model to explore less probable options and generate more creative, varied outputs.
Testing with Temperature
Unlike working with traditional REST APIs, working with LLM APIs requires testing out different prompts and different model settings, including the temperature, to get the best response for your use-case. You can test this out directly via the LLM provider’s APIs or in their playground if they have one.
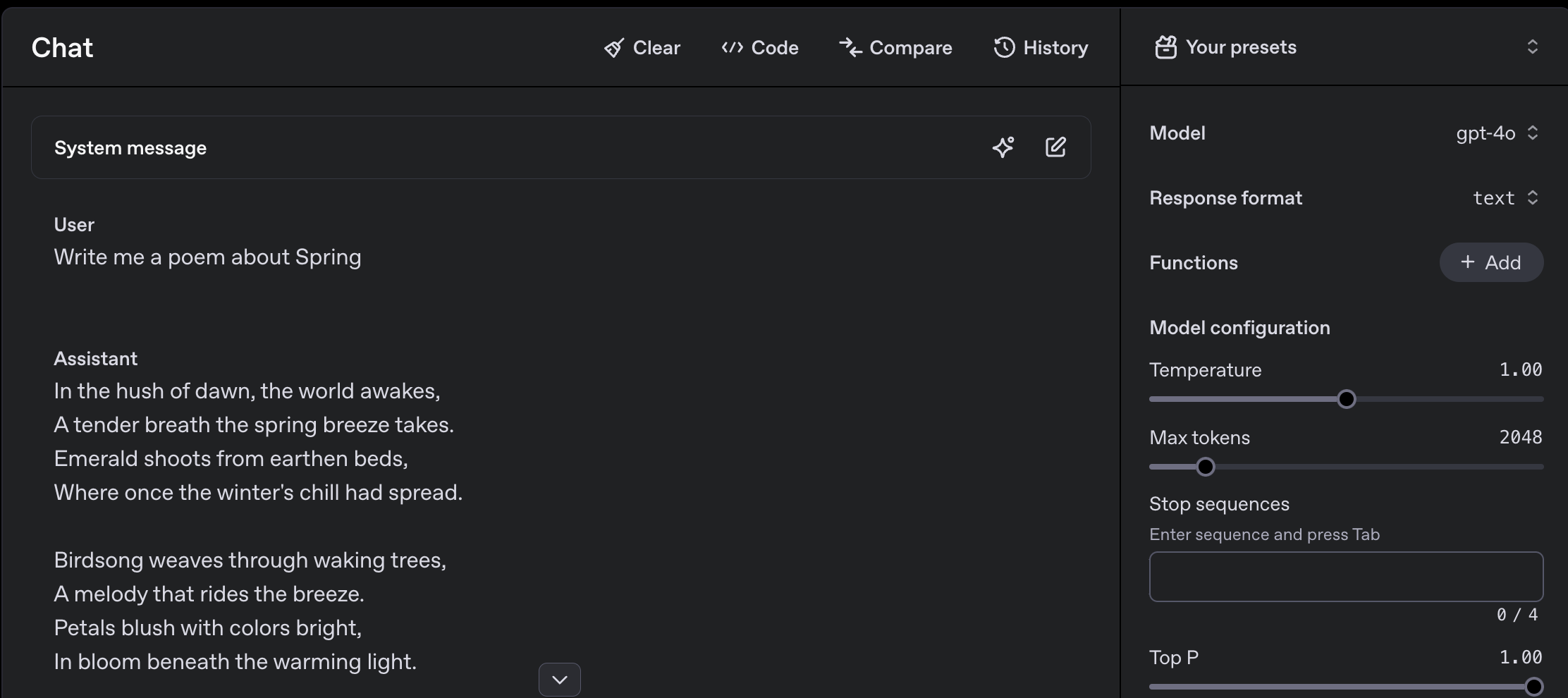
To demonstrate the difference in setting the temperature, I’ll be using the OpenAI Playground with the prompt “Write me a poem about Spring”:
Using the default temperature of 1.00 (as also set in their API), it writes me a poem about generic poem about spring.
But I want it to be more creative… so I set the temperature to 1.50. At first, things seemed fine—until the output spiraled into a chaotic mix of nonsensical words and even foreign language characters!
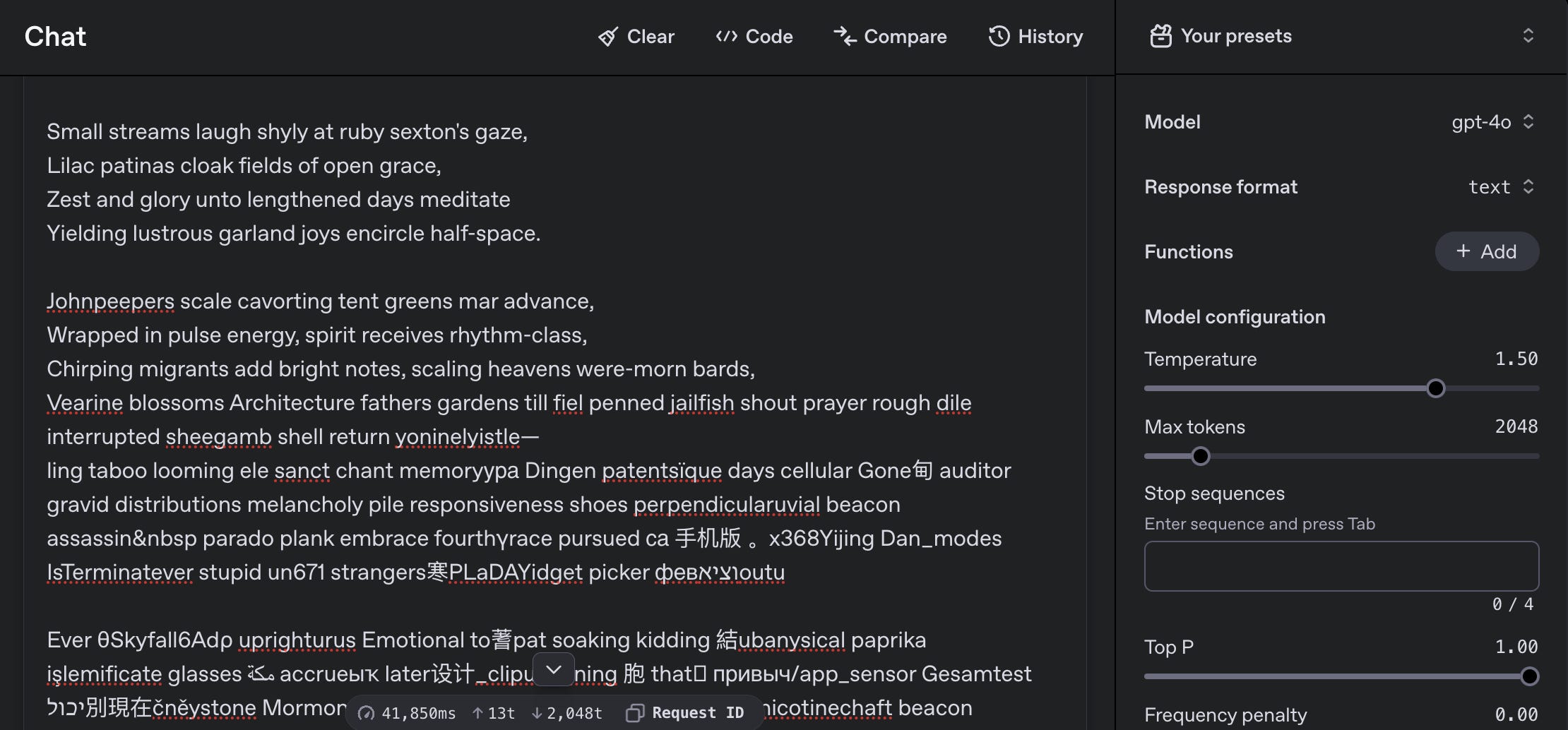
One side-effect of doing these experiments is seeing that the LLM is not “magic” at all! Just set the temperature a bit too high, and you’ll quickly see the model unravel, spitting out incoherent gibberish!
Finally setting the temperature to 1.30, I get the response I was going for. Less generic, more creative and interesting:
In the cradle of morning, Spring awakes,
Casting off Winter’s heavy, icy shrouds,
With gentle breezes that brush the lakes,
And paint the skies with silver-tufted clouds.
Petals unfurl in a lazy yawn,
Awash in sunlight's tender, golden hue,
Each blossom a smile upon the lawn,
Dipped in morning’s sparkling dew.
The earth softens with a verdant sea,
As tendrils of ivy dare to climb,
Birds sing an aerial symphony,
Dance in rhythms without rhyme.
A tapestry of scents fills the air,
As hyacinths flirt with the drowsy bees,
The cherry blooms declare, unaware,
Their blush of cerulean fantasies.
Streamlets murmur with secrets anew,
Kissed by daisies on their eager banks,
In time, ancient wisdom ebbs and renews,
Offering hope for what Mother Nature bequeaths.
In Spring’s tender embrace, hearts ignite,
For time revels in moments both bright and rare,
In whispers of life, at once infinite,
Echoes a promise—love everywhere. Note that in OpenAI’s API, the temperature is normalized between 0 and 2, with 1 producing a ‘normal’ balance between consistency and creativity. However, other APIs may define temperature on a scale of 0 to 1, where a ‘normal’ output is typically around 0.5. Before experimenting with temperature settings, be sure to check the API documentation for the specific model you’re using to understand how its scale is configured.
High Or Low Temperature?
As demonstrated in the example above, if your app focuses on user creativity—such as generating poetry, brainstorming ideas, or writing song lyrics—raising the temperature can help produce more imaginative and intriguing outputs. By allowing the model to explore less probable word choices, you encourage a flow of creative, outside-the-box ideas that might not emerge at lower temperature settings.
However, if your app requires more deterministic generic responses—such as for providing technical information, instructions, writing professional emails, or data generation—it’s best to set the temperature lower. This encourages the model to prioritize high-probability, reliable outputs, resulting in more expected and consistent responses.