
How to Enable Text Embeddings Vector Storage in Supabase
Learn how to enable and store text embeddings in Supabase, so you can perform efficient semantic search on small, structured datasets w/out needing a separate vector database.

In my previous blog post The Case for Preprocessing: Using LLMs Before Your Users Do, I talked about breaking out of the real-time mindset when working with LLMs. Instead of treating them like instant-response machines that only run when a user taps a button, I explored how we can shift some of that work to backend scripts and cron jobs.
Most apps deal with finite, structured data - whether it’s dictionary entries, PDF files, or property listings - and much of that data can be preprocessed ahead of time. By doing things like grouping similar meanings, generating summaries, or creating embeddings offline, we can cut costs, reduce latency, and make our apps faster and more scalable. In this post, I’ll show how to put that idea into practice by enabling vector storage for text embeddings in Supabase, so you can preprocess and query your data efficiently using semantic search.
You’ve probably heard of specialized vector databases like Pinecone, Milvus, and others. These are purpose-built systems designed to store, index, and search high-dimensional vector embeddings - numerical representations of complex data like text, images, or audio that capture semantic meaning. Unlike traditional databases, vector databases are optimized for similarity search, making them ideal when you need to efficiently query across millions of records. If your app deals with large-scale embedding search, this is definitely the route to take. For example if you have a movie database like IMDB, and you want the user to be able to search through ALL the movies with a natural language query.
However, in many cases, your app only needs semantic search over a relatively small, well-defined dataset. For example, an HR tool might let a manager search through a limited set of employee resumes to find specific skills within a department. Or take a personal journaling app - while someone might write daily, the total number of entries is still small. Yet, being able to semantically search past reflections (“when did I write about feeling stuck?”) can be incredibly useful. In my case, I’m building a Sanskrit Dictionary app where a single word might have as many as 100 definitions, and I want users to quickly find the most relevant ones using semantic search.
For smaller, well-scoped datasets like these, it makes perfect sense to store text embeddings directly in the relevant database rows. That way, you can fetch the embeddings alongside the rest of the data and perform semantic search right within your app—no need for a separate vector database. That’s why I was excited to discover that Supabase already supports this! With a little bit of work.
So how do you set it up? First, select your project then go to “Database” in the side menu:
From the Database menu, select Extensions and type in “vector” into the search:
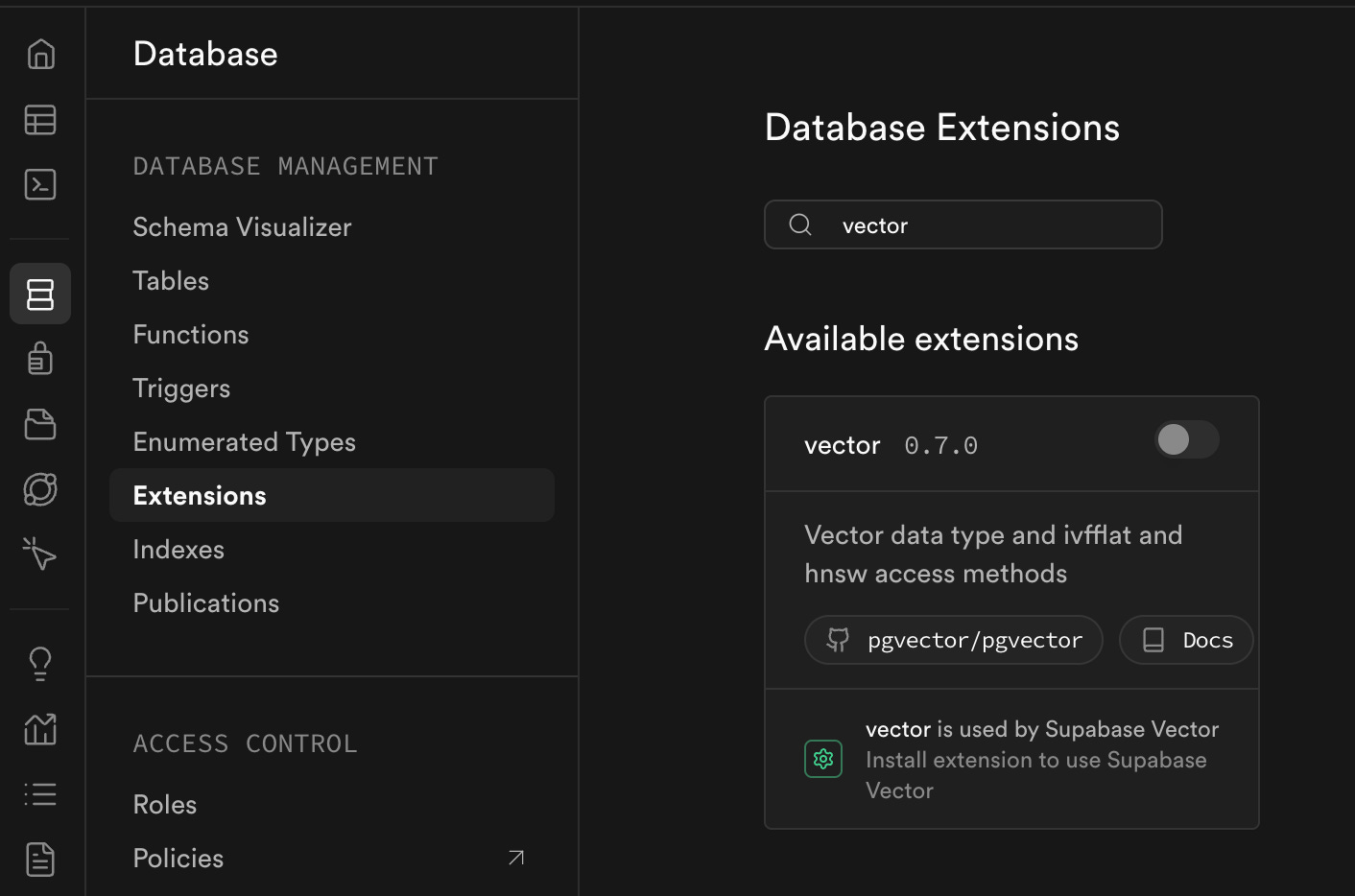
Enable it!
Now you can use the SQL Editor to add a vector column to any table with specified dimensions. For example, if you’re using OpenAI’s text-embedding-3-small model, your SQL statement will be as follows:
ALTER TABLE yourtable ADD COLUMN embedding vector(1536);If you’re using OpenAI’s text-embedding-3-large model, change this to:
ALTER TABLE yourtable ADD COLUMN embedding vector(3072);However, keep in mind that the large model requires significantly more storage and may introduce latency when querying rows. If you’re storing embeddings alongside other data, be sure to select only the columns you need when querying - avoid pulling the embedding unless necessary. Alternatively, you can store embeddings in a separate table keyed by the same IDs to keep your primary table lean and avoid accidental latency by pulling the embedding column when unnecessary.
That’s it! Now you can easily run an OpenAI Batch API update to add embeddings for all the values in your table (how to do that and beyond in the next blog post!).