
How to Integrate Reasoning into Cheaper Non-Reasoning Models
Reasoning models like OpenAI’s o-series give better responses compared to traditional LLMs, but their high cost and slowness are a barrier—learn how to leverage cheaper, faster LLMs for better results

New reasoning models like OpenAI’s o-series and DeepSeek’s R1 are reshaping the landscape of LLMs. By first thinking through the problem before responding, these models can generate much more accurate and thoughtful answers to much more complicated user queries. However, for us as mobile developers, integrating these models into our apps presents two key challenges:
High Latency: If you’ve used a reasoning model, you’ve probably encountered cases where it thought for as long as 2 minutes or longer! As iOS developers, adding an extra 2 minutes of waiting for a response is not a good mobile-based user experience.
High Cost: These models are significantly more expensive compared to other much cheaper non-reasoning models already available on the market, including open source alternatives. For example, using OpenAI’s o1 model costs $60 / million output tokens!
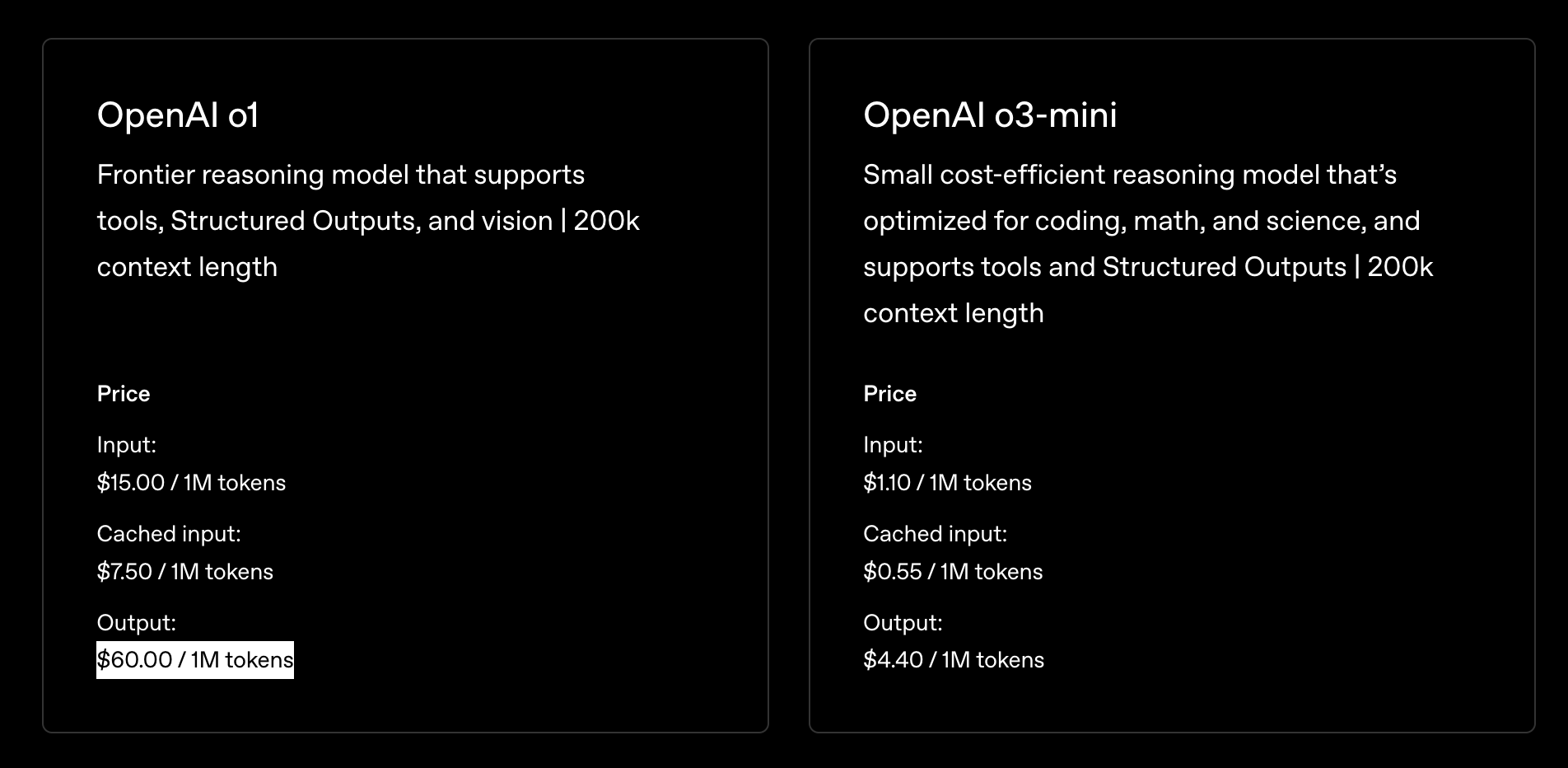
And since these models generate “thinking” tokens as part of their reasoning process, the output isn’t just a quick, straightforward answer. Instead, it includes a large number of extra tokens, further driving up costs.
However, most apps can work around the need for reasoning models. By understanding how these models work, they can apply similar techniques to standard models and still achieve excellent results. Here’s how:
How Reasoning Models Work
Understanding how LLMs are trained is key for every developer. The more you know about their training, the better you can work with them through both their capabilities and limitations. Make sure to take the 3 hours to watch Andrej Karpathy’s Deep Dive into LLMs like ChatGPT if you haven’t already!
Towards the end of his video, Andrej Karpathy explained how reasoning models emerged. These models were given problems with clear answers, which they were allowed to solve in any way—even if that meant using many tokens. The solution paths that led to correct answers were rewarded, while those that resulted in errors were discarded:
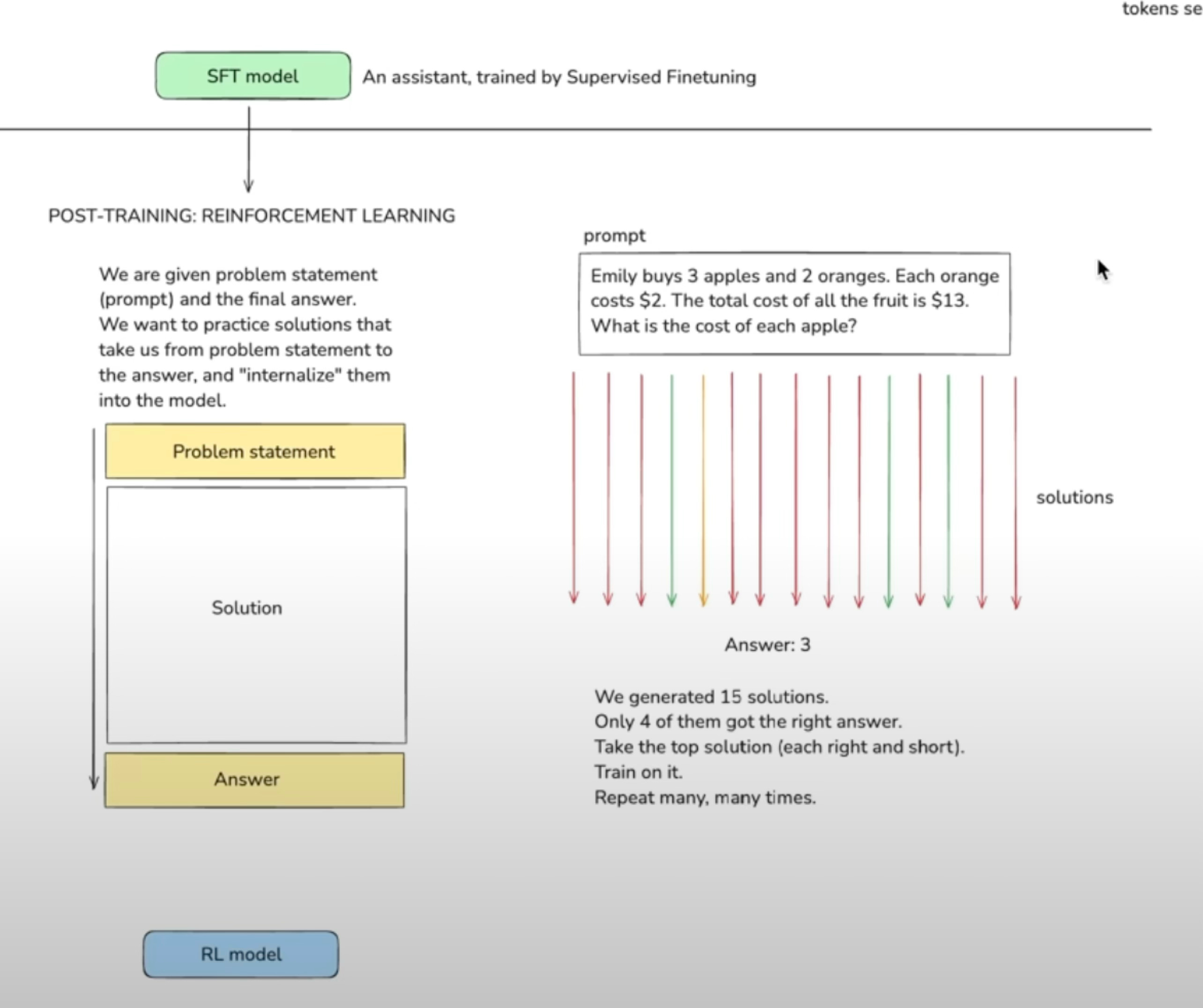
When the answer paths that led to correct solutions were analyzed, it was discovered that they contained “thinking” tokens—extra words generated by the model to clarify its reasoning process.
This is not surprising - it was previously discovered that telling the model to “think step by step first” before generating a response led to better answers. So how this be applied to using cheaper non-reasoning models? The answer is simple:
How To Include Reasoning in Non-Reasoning Models
As a demo, I built an app called CodeLegends, which retrieves Wikipedia articles about famous computer scientists then uses Google’s Gemini 2.0 model to extract the computer scientist’s date of birth, nationality, notable achievements, and education.
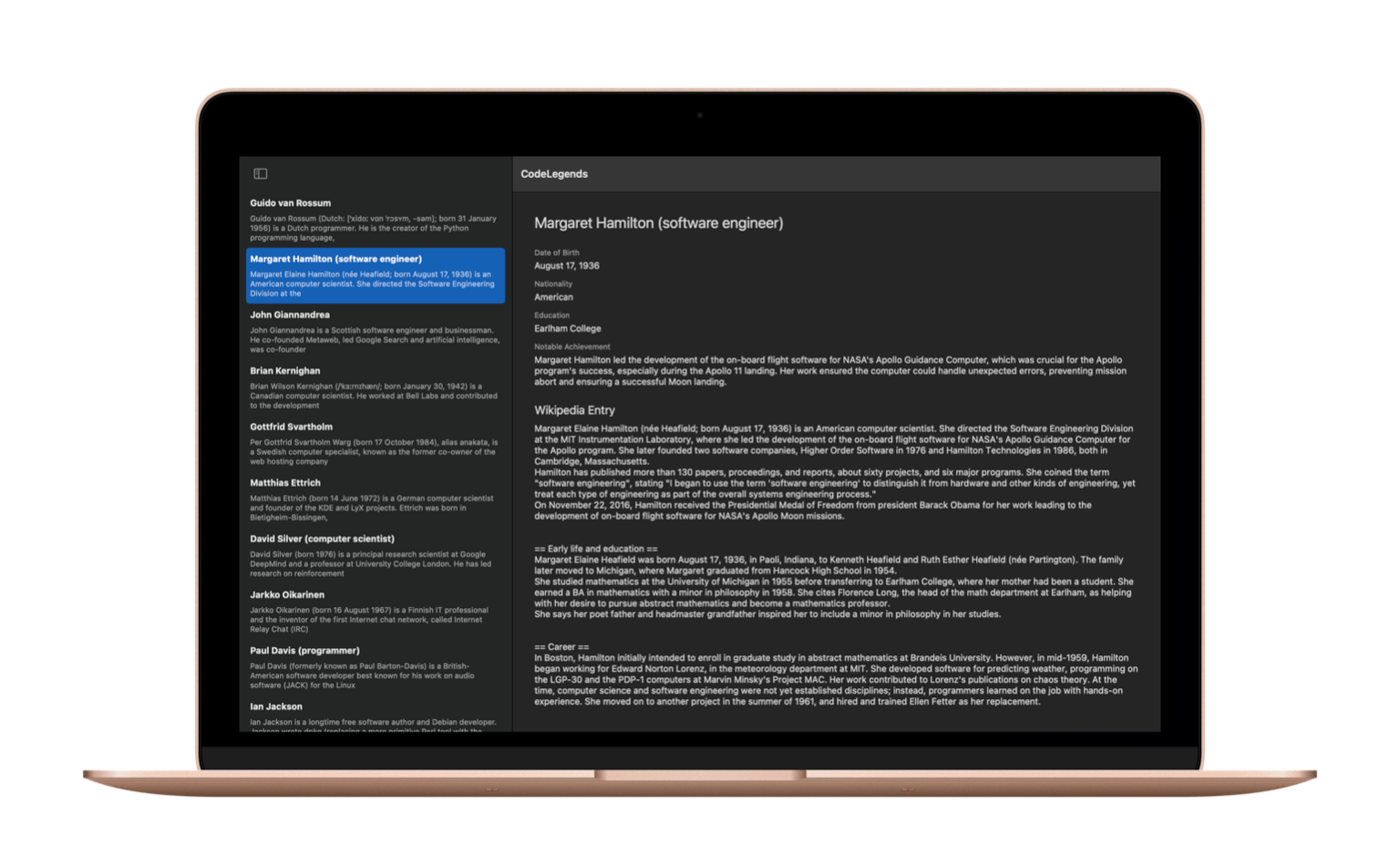
Initially, I used OpenAI’s GPT-4o model to extract the computer scientist’s information from the Wikipedia article, which did really well. But it was too expensive:
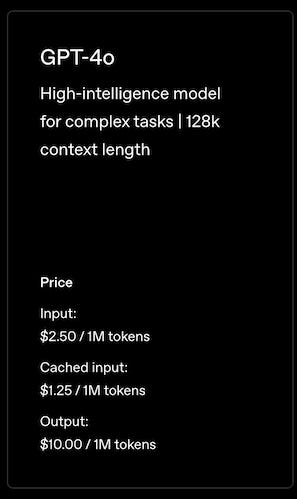
It also has a very small context window of 128k tokens. This is more than enough for this app using a Wikipedia article, but it might become a big problem when I want to include other larger sources of information about famous computer scientists in the future.
So I decided to switch to Google Gemini’s Flash 2.0 model, which is much much cheaper:
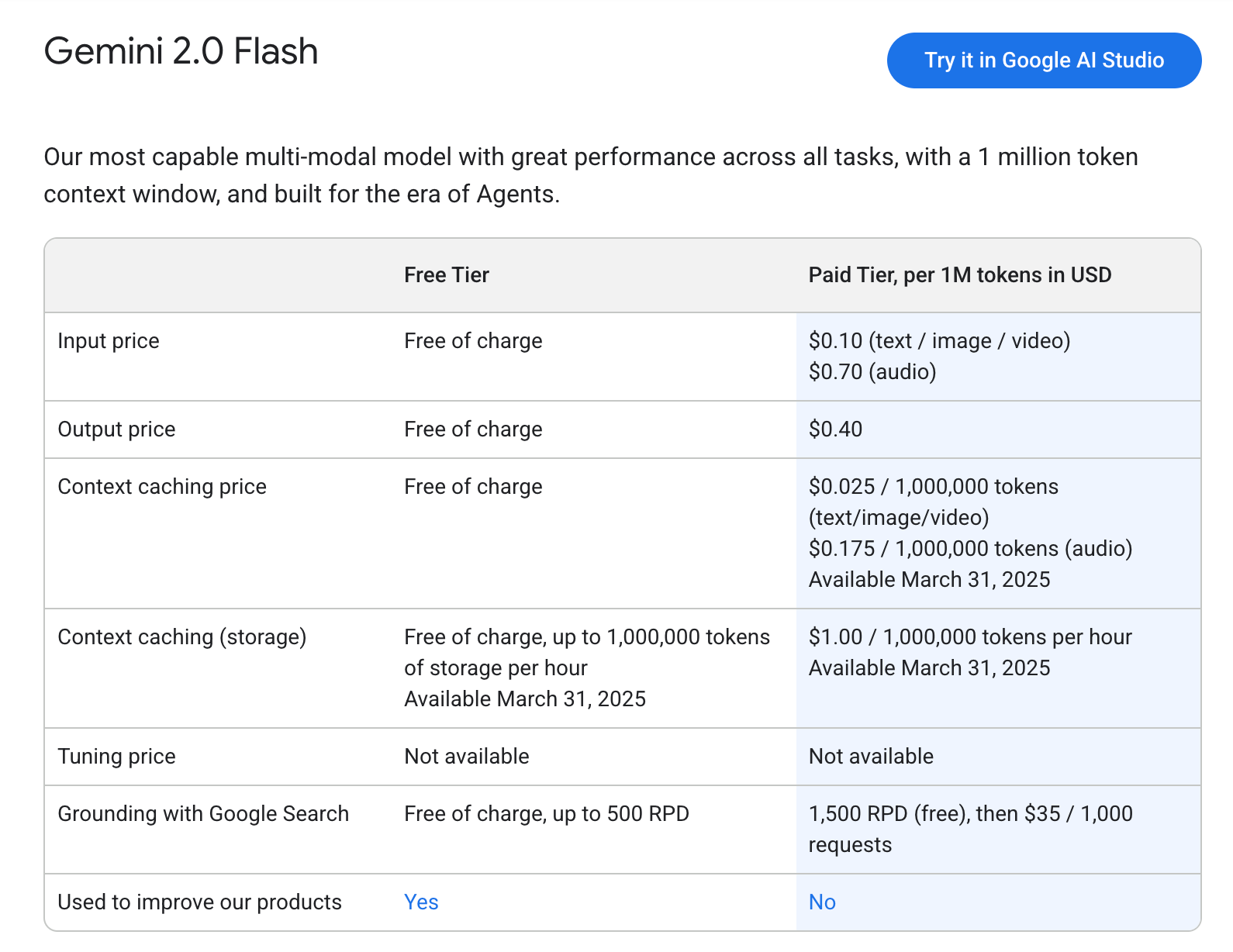
My output tokens would now go from $10 / 1M to only $0.40 / 1M with the context length of 1 million tokens, allowing me to add much more data about each computer scientist in the future without any chunking.
But when I switched to the Gemini Flash 2.0 model, I wasn’t satisfied with the “Notable Achievement” summary it provided. For example, I found the wording of this particular achievement too abrupt and rough.

So to solve this, I added one more field to my structured output:
"notable_achievements_analysis": [
"description": "Detailed analysis of the computer scientist's notable achievements and contributions to the field.",
"type": "STRING"
]Thinking back to how models need to “think” to return better results, I added a field I didn’t need - notable_achievements_analysis - to add the “thinking” without needing a thinking model. Note that this field needs to be added before the final “notable_analysis” field so that the model first gets the “thinking” tokens before giving the summary.
This worked really well! The new summary sounded great:
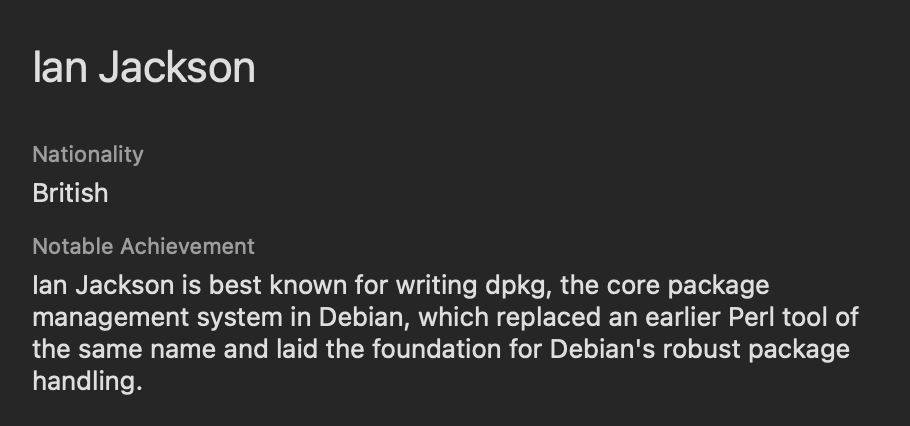
Here is another side-by-side example:
Before adding analysis:

After adding analysis:

Conclusion
Reasoning models like OpenAI’s o-series and DeepSeek’s R1 are undeniably pushing the boundaries of what LLMs can achieve, offering more nuanced and accurate responses by “thinking” through problems first. However, as mobile developers, we must balance these benefits with practical considerations such as cost and latency.
By understanding how these models work—and by experimenting with techniques like step-by-step reasoning in traditional LLMs—we can often achieve comparable results without incurring steep expenses.
CodeLegends is just one example of how to integrate reasoning into standard models for structured data extraction. There is a lot of room for creativity here.
The full code-base for the CodeLegends app is available to paid subscribers:
Happy building!