
Building Safer iOS Apps: Using OpenAI’s FREE Moderation API in Swift
Learn how to integrate OpenAI’s Moderation API into your Swift apps to effectively manage user-generated content and maintain a safe platform environment.

As large language models (LLMs) become increasingly open and uncensored, and as users find ways to bypass their restrictions, it’s crucial to ensure that user inputs align with your app’s values and guidelines. Implementing robust moderation helps maintain the integrity of your platform and provides a safe and respectful environment for all users.
Google’s Gemini API includes adjustable safety settings designed to filter content across categories such as harassment, hate speech, sexually explicit material, dangerous content, and civic integrity. By default, these settings block content with a medium or higher probability of being unsafe. However, many developers and users have found these filters to be overly aggressive, many times flagging benign content as unsafe.
However, disabling these safety filters increases the risk of exposing users to harmful content. To mitigate this, consider implementing an external moderation system. OpenAI offers a FREE Moderation API that can identify potentially harmful content in text and images, allowing you to take corrective actions such as filtering content or intervening with user accounts responsible for the offending material.
By integrating OpenAI’s Moderation API, you can balance content accessibility with user safety, ensuring your application remains both functional and responsible.
OpenAI’s Moderation API comes with two models:
omni-moderation-latest: This model and all snapshots support more categorization options and multi-modal inputs.text-moderation-latest(Legacy): Older model that supports only text inputs and fewer input categorizations. The newer omni-moderation models will be the best choice for new applications.
The API is simple - simply pass the user’s text or image input - you can do this via the Create Moderations endpoint or via the AIProxySwift library as follows:
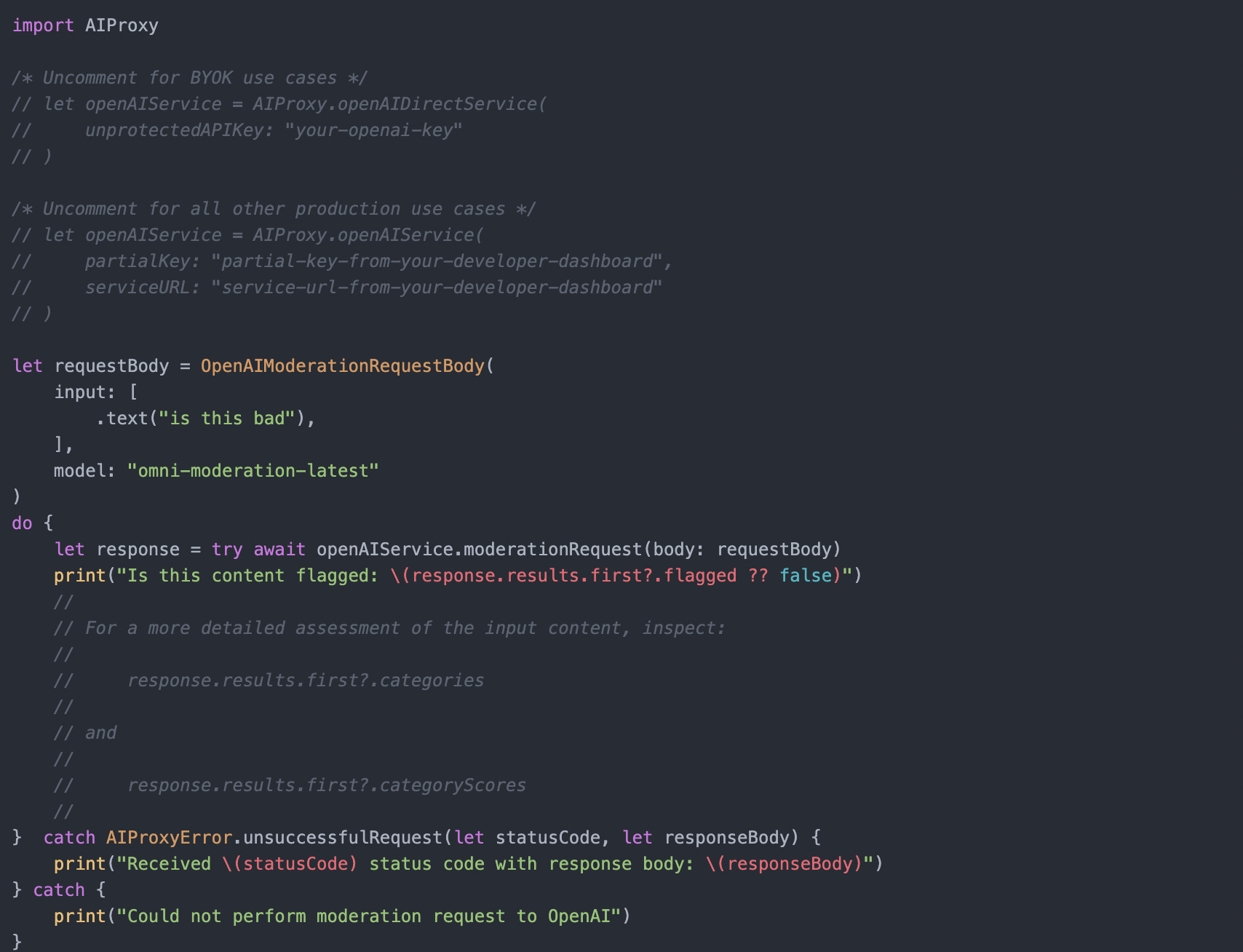
The model will return back the following JSON object:
{
"id": "modr-0d9740456c391e43c445bf0f010940c7",
"model": "omni-moderation-latest",
"results": [
{
"flagged": true,
"categories": {
"harassment": true,
"harassment/threatening": true,
"sexual": false,
"hate": false,
"hate/threatening": false,
"illicit": false,
"illicit/violent": false,
"self-harm/intent": false,
"self-harm/instructions": false,
"self-harm": false,
"sexual/minors": false,
"violence": true,
"violence/graphic": true
},
"category_scores": {
"harassment": 0.8189693396524255,
"harassment/threatening": 0.804985420696006,
"sexual": 1.573112165348997e-6,
"hate": 0.007562942636942845,
"hate/threatening": 0.004208854591835476,
"illicit": 0.030535955153511665,
"illicit/violent": 0.008925306722380033,
"self-harm/intent": 0.00023023930975076432,
"self-harm/instructions": 0.0002293869201073356,
"self-harm": 0.012598046106750154,
"sexual/minors": 2.212566909570261e-8,
"violence": 0.9999992735124786,
"violence/graphic": 0.843064871157054
},
"category_applied_input_types": {
"harassment": [
"text"
],
"harassment/threatening": [
"text"
],
"sexual": [
"text",
"image"
],
"hate": [
"text"
],
"hate/threatening": [
"text"
],
"illicit": [
"text"
],
"illicit/violent": [
"text"
],
"self-harm/intent": [
"text",
"image"
],
"self-harm/instructions": [
"text",
"image"
],
"self-harm": [
"text",
"image"
],
"sexual/minors": [
"text"
],
"violence": [
"text",
"image"
],
"violence/graphic": [
"text",
"image"
]
}
}
]
}The moderation categories are as follows:
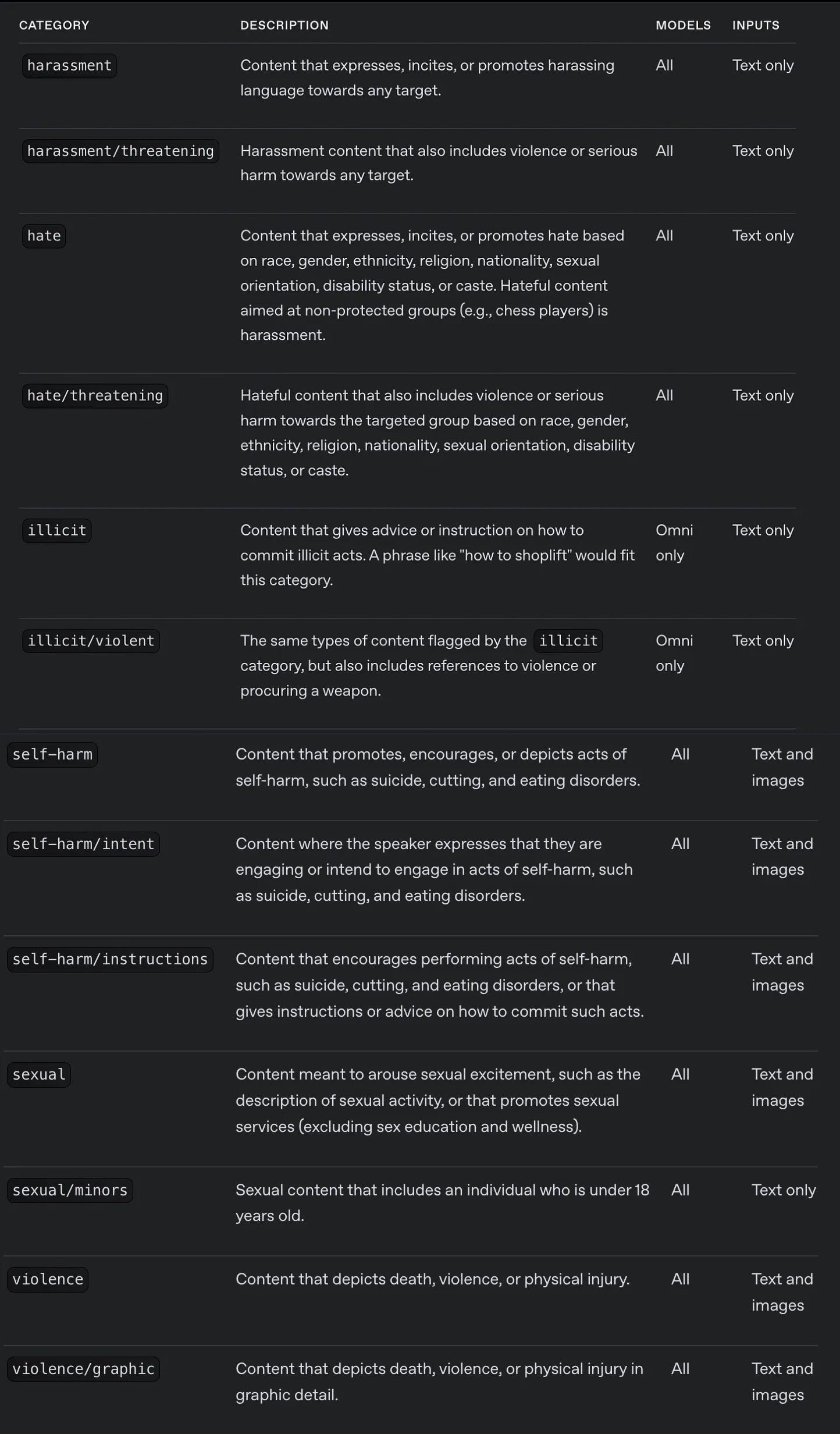
The response from OpenAI’s Moderation API includes category_scores, which are numerical values ranging from 0 to 1. These scores indicate the model’s confidence that the input violates OpenAI’s policy for each specific category; higher scores represent greater confidence. While these scores provide valuable insights, it’s important to note that OpenAI may update the underlying model over time, potentially affecting these scores. Therefore, any custom policies or thresholds based on category_scores may require periodic recalibration to maintain accuracy and effectiveness.
Integrating OpenAI’s Moderation API with the Chat Completions API allows your application to handle user inputs more effectively. By running both APIs concurrently, your system can promptly assess and respond to potentially harmful content. If the Moderation API flags an input, your application can implement appropriate measures, such as informing the user about the flagged content or enforcing policies like a “three-strikes” rule for repeat offenders.
This was incredibly helpful! Thanks for sharing.