


What are Tokens?
Tokens are at the heart of how LLMs are so powerful. Yet - they are not “logical” in the way we would like them to be... Knowing how they work is critical for every developer planning to build w/ AI!

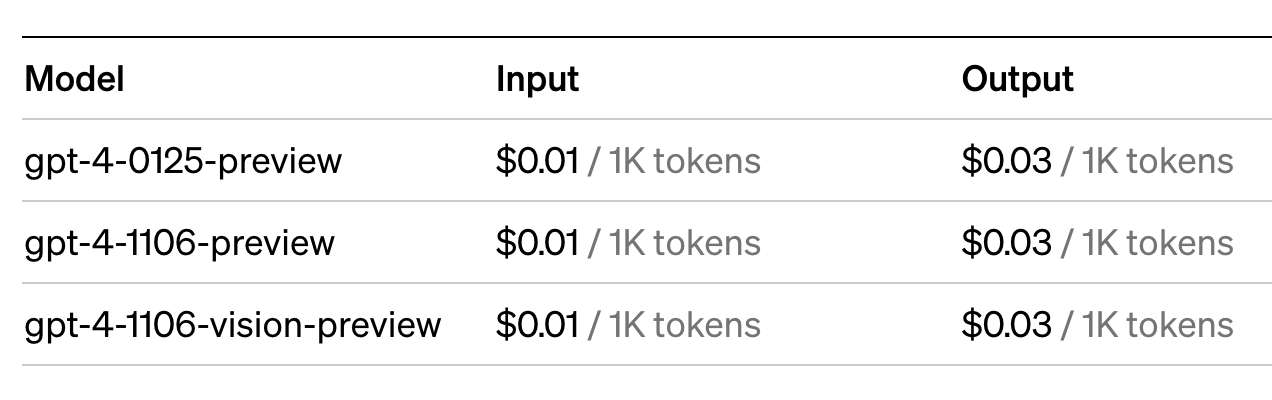
If you’re interested in using an API like OpenAI to integrate AI functionality into your app, you will see that the pricing is based on tokens. For example, here is OpenAI’s pricing model for using GPT-4 Turbo:
You may have also seen AI-related tweets / blog / news about tokens: