
Why does AI Hallucinate?
If you're considering adding AI into your app, make sure to understand how AI can hallucinate and how to adjust for that so that you don't end up losing money in legal fees!

We’ve all experienced this by now. We ask ChatGPT to generate some Swift code, especially using a new framework we haven’t worked with before, and it gives back legitimate-looking code. But when we copy and paste the code into our codebase, the function it came up with doesn’t actually exist!
Swift code is just an example, but this can happen for anything. One time, for example, I was planning a road trip and it gave me an amazing destination I was really excited to go to only to find out it’s been closed for years when I looked into booking accommodations.
This phenomenon of AI generating false or misleading information is called Hallucinations. The biggest problem with this is that the AI doesn’t tell you when it’s telling the truth or not. It’s just as confident hallucinating as it is telling legitimate real-world information. So why does this happen?
To understand this, we need to understand how Large Language Models (LLMs) like ChatGPT work under-the-hood. I highly recommend watching Intro to Large Language Models by Andrej Karpathy, one of the founding members of OpenAI. While I won’t go too deep into it, my goal is to give a basic understanding so that you are aware of why certain bugs happen and can adjust for them (if possible) in your own app as you integrate AI.
What are Large Language Models?
As Andrej Karpathy puts so well in his video, we can think of Large Language Models as the compression of the internet. In other words, to create an LLM, we take the internet (by scraping it) and process it in big data center. This is the costly part that only big companies like Google / Facebook etc could do before. The cost is ~2 MILLION dollars, and it takes about 12 days. The output is a very big file - ~140GB.

Lucky for us, some of these companies, including Meta, have released their LLM as open source for anyone to use.
During the processing stage, words are converted into tokens (small text units) which are then mapped to numbers. Using these large arrays of numbers (a mathematical map to text) and the logic that was included in generating the model on what to prioritize, and many mathematical operations later, a brain-like neural network is created, which is the LLM.
The words (via numbers or vectors) are connected to other words. You can play around with an example word network on the TensorFlow Embedding Projector. For example, when I click on the word “leaf”, I can see that is closely connected to the words “leaves”, “trees”, and “oak”, but are further away from words like “ants”.
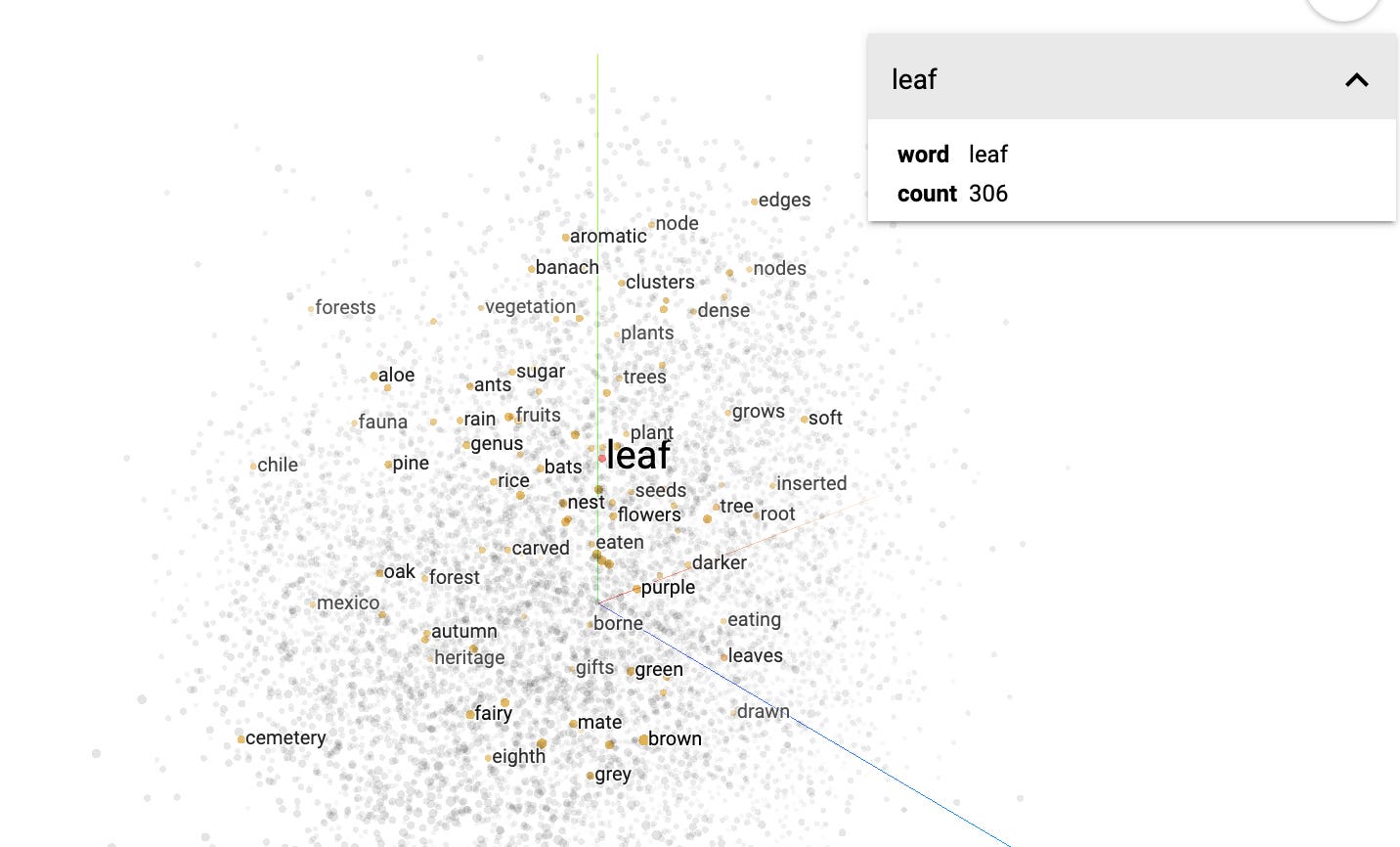
By putting words and sentences into multiple dimensions of vector space, the model can calculate probable words that are related.
The LLM can then take an input of a word or a sentence, which is converted into arrays of numbers (vectors), process it through its complex neural network of word connections it’s been trained on, do probability calculations, and come up with an output of the next set of words as shown in the example below:
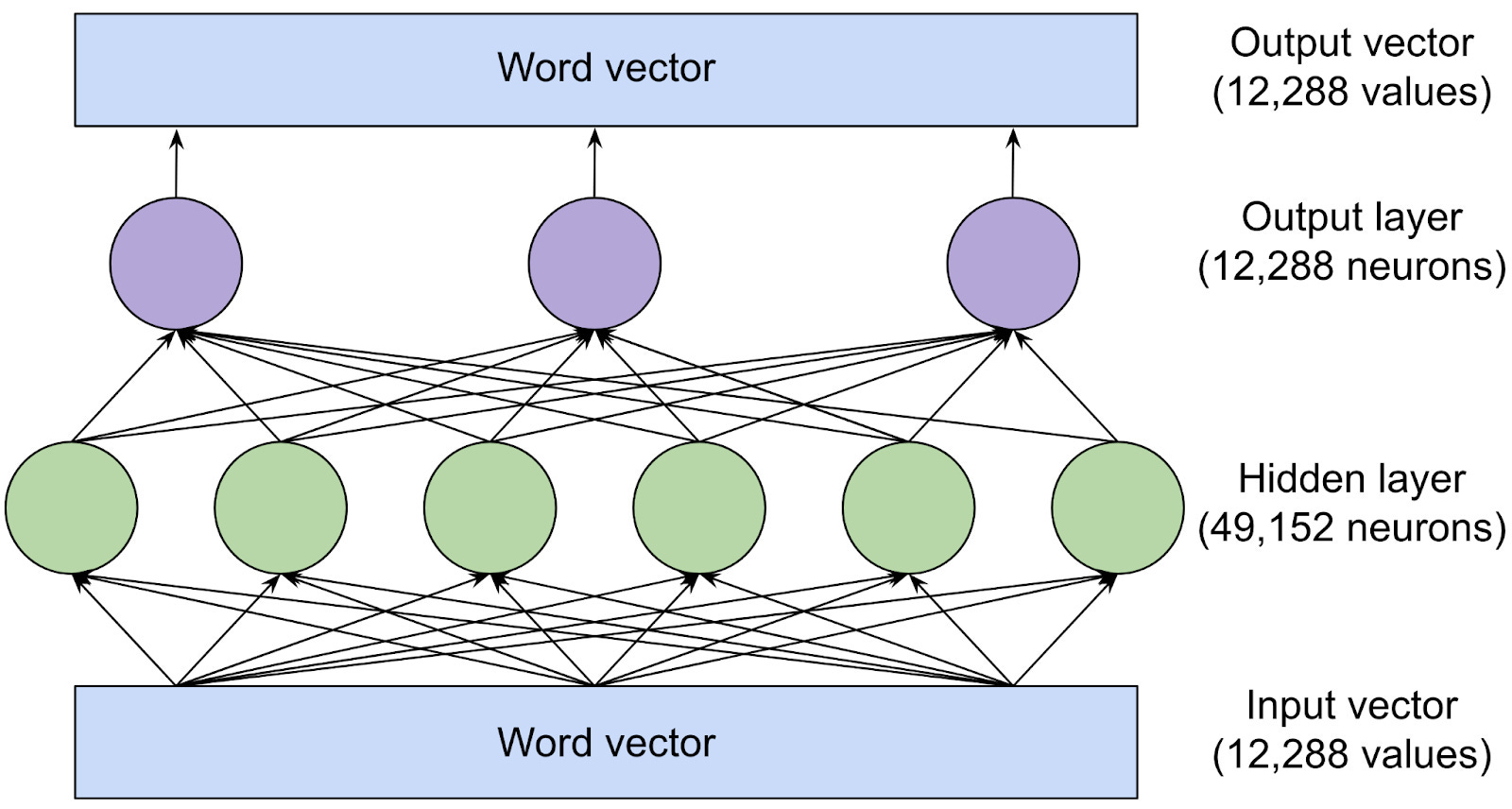
So to summarize, while apps like ChatGPT are extremely impressive and seem magical, under-the-hood their language model is spitting out the next probable set of words. It can be thought of as an extremely complex autocomplete.
In fact, one of OpenAI’s earlier products was a text box where you input a word or sentence and it will complete it for you. You can still play with it in the OpenAI Playground if you change to the Complete model:
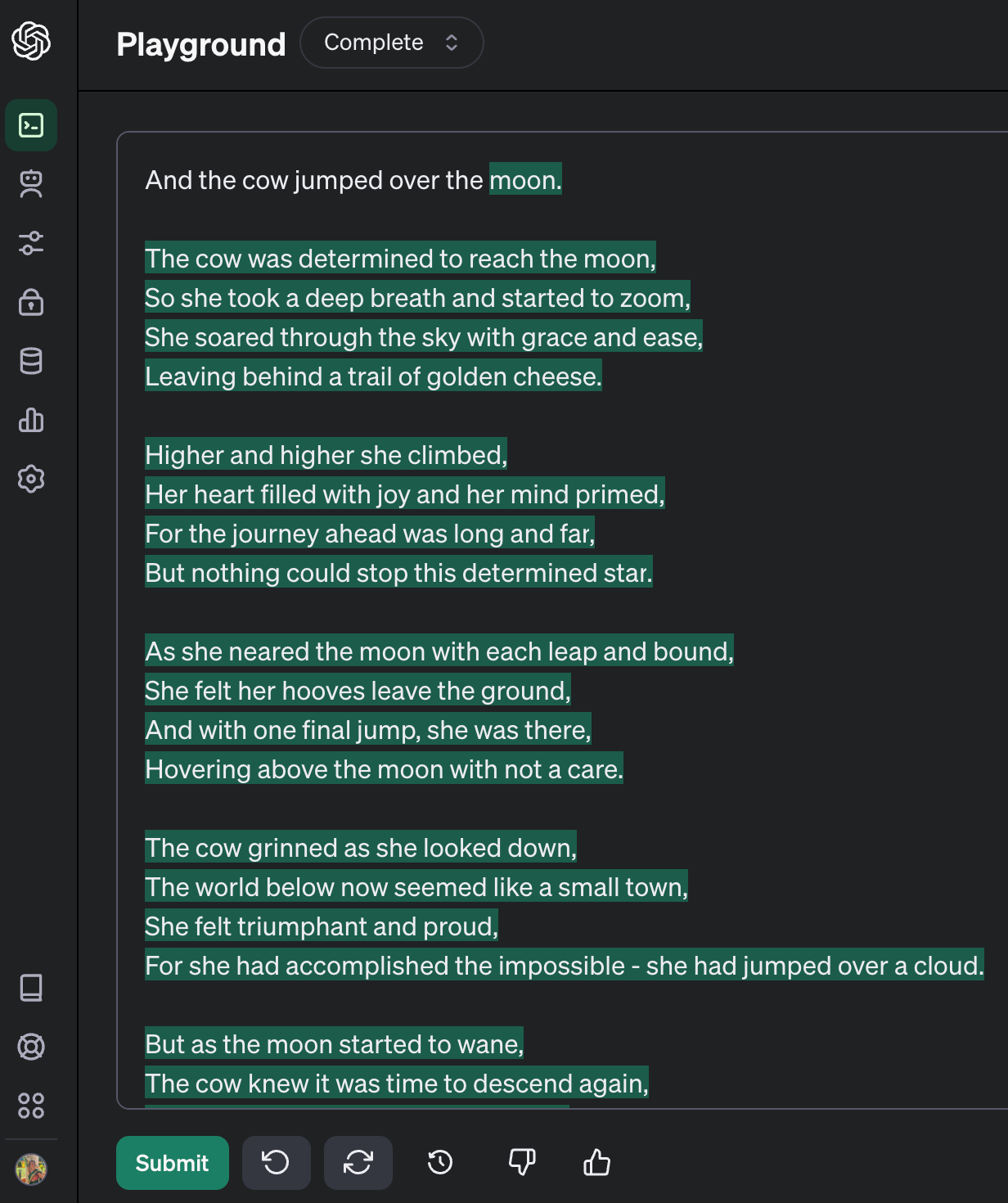
Here I typed in only “And the cow jumped over the” and the model completed the rest. It “knew” / calculated based on all the data it’s been trained on that this line came from a nursery rhyme and created a poem in a rhyming style that would be nice for children.
The Hallucination Problem
So now that we understand that LLMs are basically big probably machines that are auto-completing an input, the Hallucinations start to make sense. The model is not “thinking” in the way that a human does, so it doesn’t “care” whether its output is factually correct or not. It is simply giving the most probable answer. This works well for the most part, which ChatGPT has shown us, but sometimes it just ends up making things up…
If you’re an expert in the field you’re trying to query, then this is not as big of a problem. I can easily understand which function in the generated Swift code is wrong and how to look at the documentation to find the correct answer. But if you are new to a topic, you will have no idea.
For example, let’s say I want to learn a little bit about Indian History. I don’t have a background in Indian History, so anything it tells me about Indian History will sound correct to me. And since most of what it’s saying is correct, I won’t have any idea when it tells me a random incorrect thing. I won’t even know to fact-check it myself as I trust the AI.
As of the way LLMs work right now, there are ways to reduce hallucinations, but not entirely eliminate time. Check out the recent paper Hallucination is Inevitable: An Innate Limitation of Large Language Models.
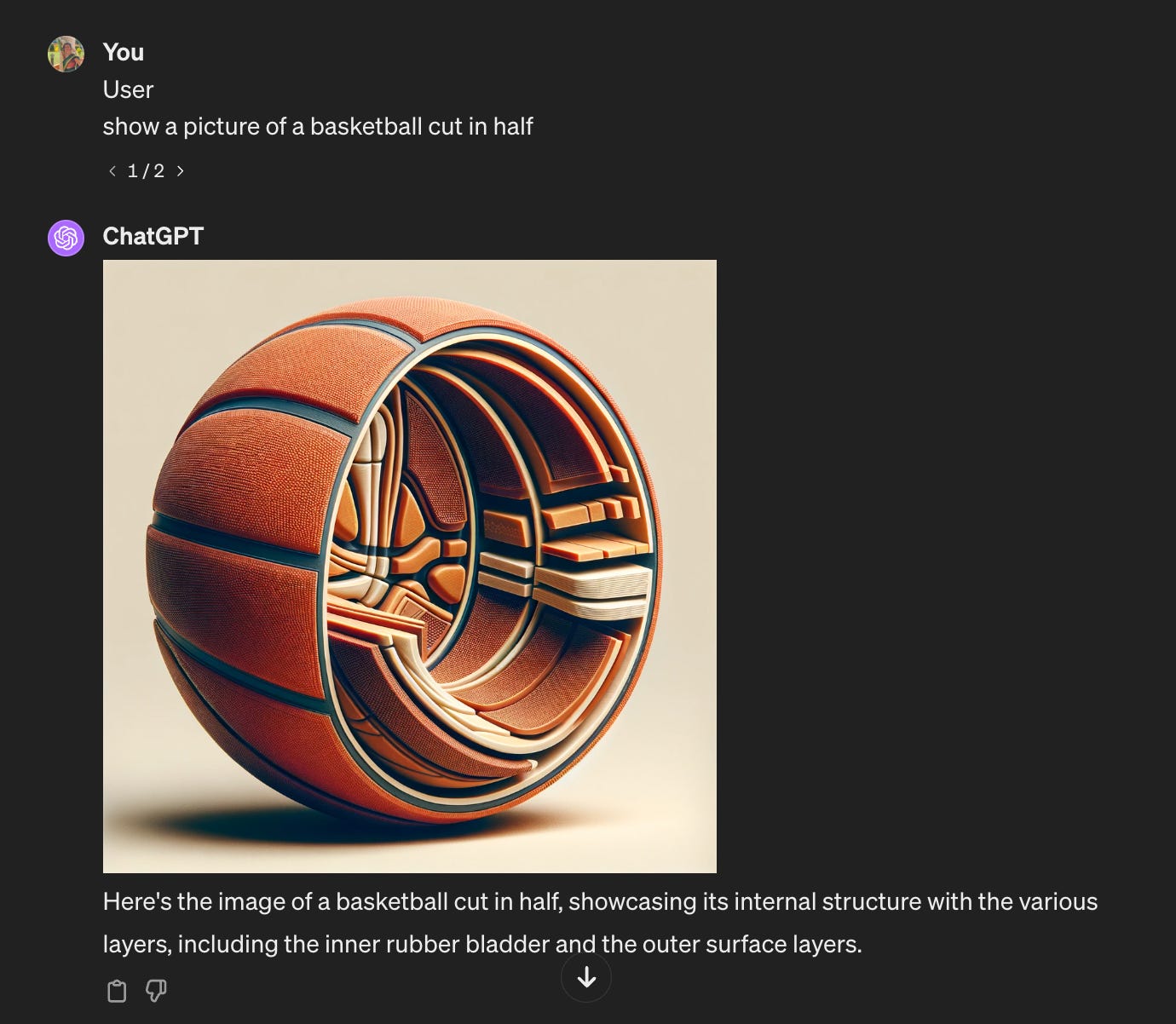
This further becomes a problem with image generation, which combines LLMs with Stable Diffusion. Have you seen the 6-fingered humans? Or for example, ask ChatGPT to generate an image of something that is obvious but is not pictured often, such as what the inside of a basketball looks like:
Or what the inside of a propane tank looks like:
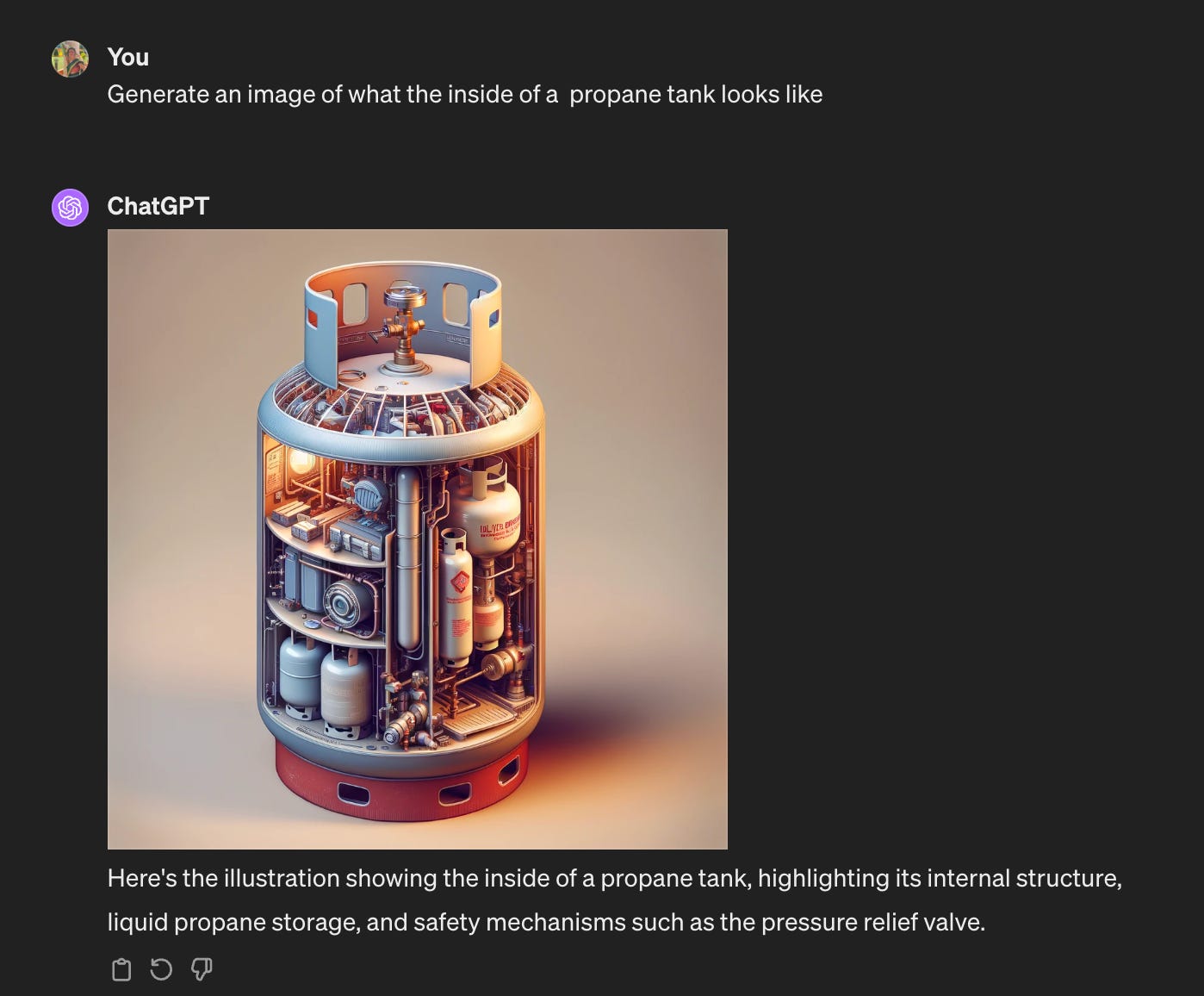
Check how it is very confident in its answer, giving justification of the internal structures.
So depending on the product you’re building using AI, it is extremely important to know about and communicate about hallucinations to your users. One legal issue has already come up in the case of Air Canada, where the court forced them to honor the refund policy invented by the AI chatbot on their website.
As I’ve been using Supabase for my backend recently, I’ve noticed that they have an explicit disclaimer in their AI, which I really appreciate as a user and would consider putting in my own app as needed:
Putting some type of Legal disclaimer to the tune of “we are not responsible for anything the AI chatbot says” might also make sense.
Another way to go is to use AI more implicitly in your app, without direct user input, with strong prompts and specific structured data that you have tested. Also - have a feature for users to report inaccurate AI outputs that you can go back and check afterward to fix your prompts. These are just some ideas. Have other ideas / thoughts, leave them in the comments!