
Beyond OCR: Automating PDF Data Extraction in Swift with Gemini 2.0
Explore how to use Google Gemini 2.0 in Swift to extract structured data from PDFs, including invoices and handwritten tax forms

A few days ago I wrote about the new Google Gemini 2.0 model’s capability to do OCR scanning, formatting, and chunking all in one go. See Harnessing AI for Intelligent PDF Processing in Swift: From OCR to Context-Aware Chunking.
Now, it turns out that Gemini 2.0’s PDF processing capabilities go even further. In his insightful blog post, From PDFs to Insights: Structured Outputs from PDFs with Gemini 2.0, Philipp Schmid of the Google DeepMind team reveals even more PDF-related capabilities and tips. Unfortunately, the blog post provides only Python code samples, so I’ll be rewriting it with his step-by-step examples using Swift instead.
The Setup
To interface with the Gemini model, I’ll be using the AIProxySwift library - the reason I like using AIProxy is that it provides a way to interface across many AI providers in Swift, making it easy to mix-and-match AI clients and models as needed.
More importantly, it’s a service for storing your API keys more securely on their proxy server, making it super easy to get started as an indie developer. For this demo, however, I’ll be using the unsecured API key client option—check out AIProxy’s videos and examples to learn how to store your API key via their web interface and switch to a secure client.
You can get the Gemini API key here. As Philipp Schmid points out, the Gemini Flash model is available via free tier with 1,500 request per day, so you don’t need to pay anything to get started!
The code to set up your Gemini client with defined model and specifying the PDF mime type (will be needed later to work with your PDF) is now just a few lines of code:

Upload the PDF
After a user selects a PDF file locally, save it to a designated path within your app’s directory. Then, use that URL to upload the PDF to the Gemini file storage service:
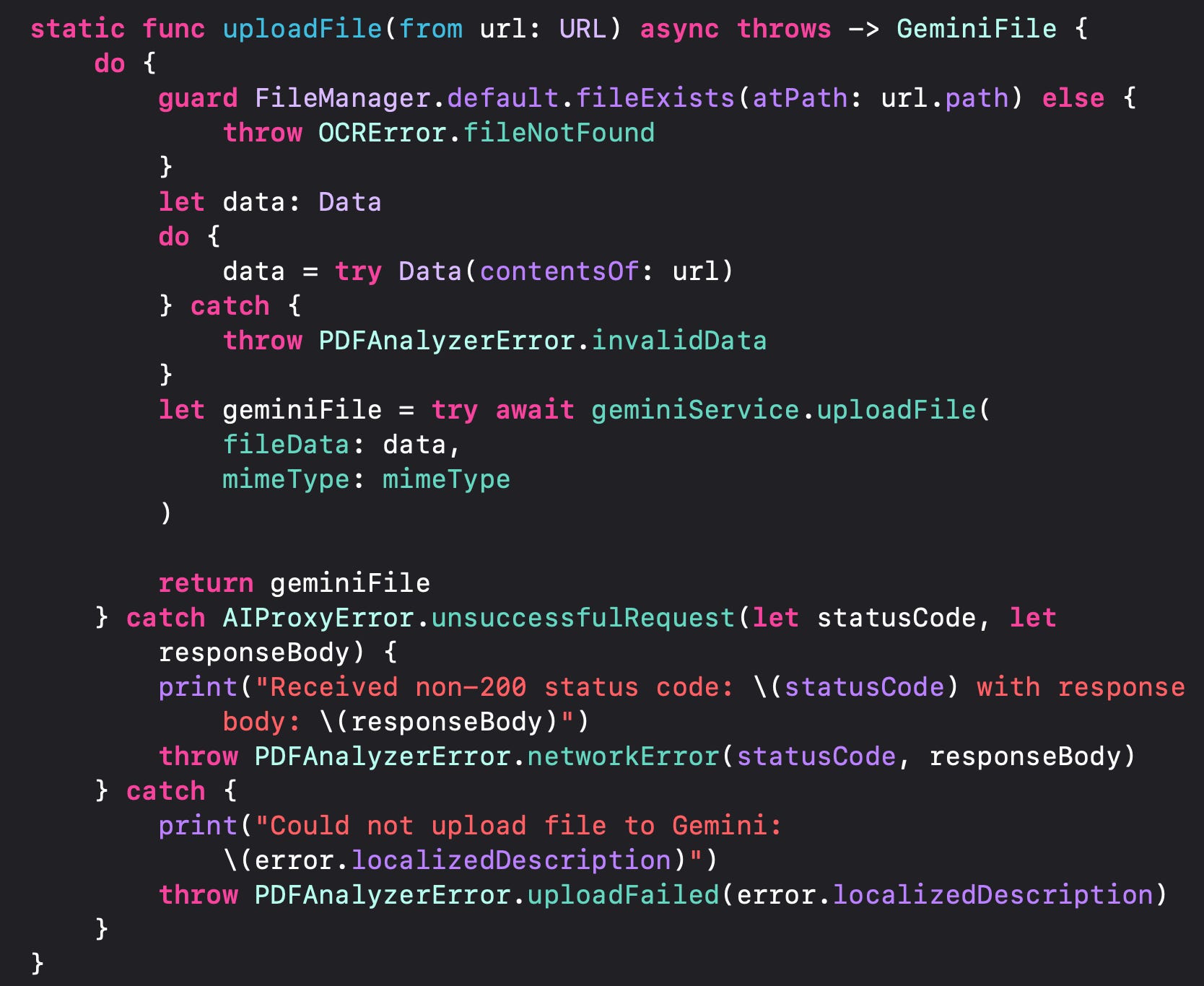
The Gemini service returns a GeminiFile object that includes the file’s unique URI, which serves as its identifier for all future references to this file in Gemini’s storage.
Make sure to note the following important details about the Gemini file storage from Philipp Schmid’s blog post:
Note: The File API lets you store up to 20 GB of files per project, with a per-file maximum size of 2 GB. Files are stored for 48 hours. They can be accessed in that period with your API key, but they cannot be downloaded. File uploads are available at no cost.
Extract Structured Data from an Invoice
Following the example in Philipp Schmid’s blog post I tested out extracted structured information from this invoice:
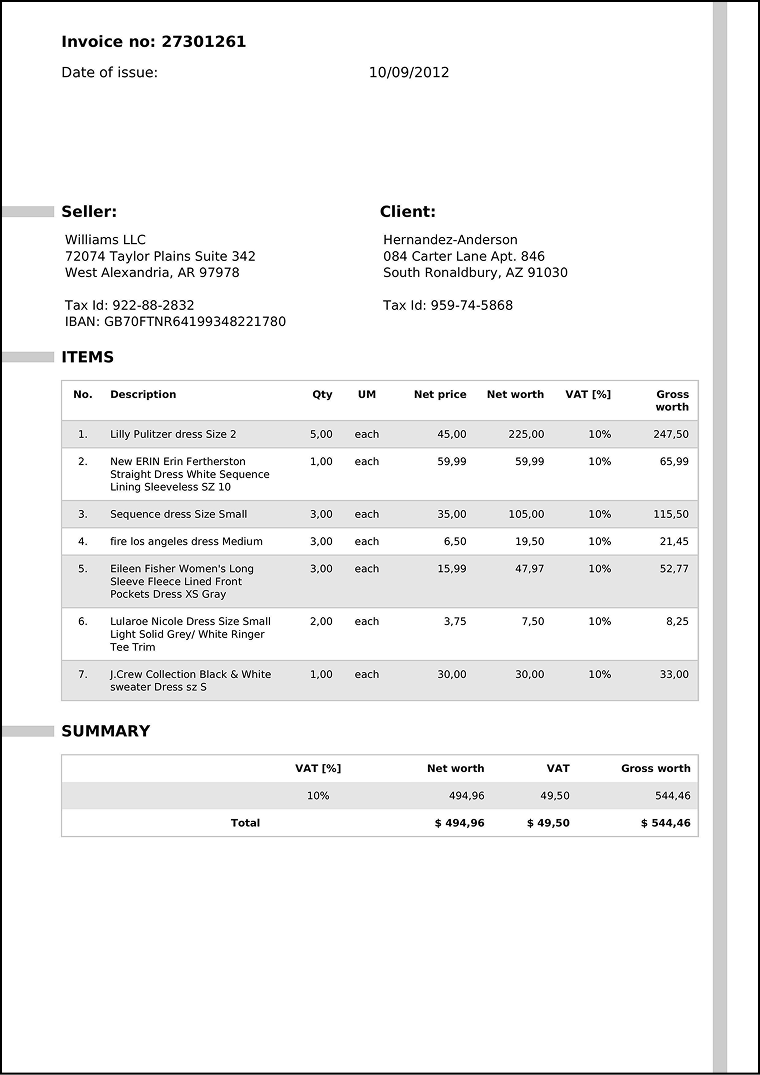
The first challenge I encountered was that the AIProxy library I’m using for Gemini calls doesn’t yet support the necessary properties for structured outputs. However, the library is open source and it’s a trivial addition, so I’m sure it’ll be added soon. In the meantime, the Gemini documentation specifies that placing the json schema right into the prompt is fine.
So I specified my schema of what I wanted output from the invoice in String format as follows:
static let invoiceSchemaString = """
{
"type": "OBJECT",
"properties": {
"invoice_number": {
"description": "The invoice number e.g. 1234567890",
"type": "STRING"
},
"date": {
"description": "The date of the invoice e.g. 2024-01-01",
"type": "STRING"
},
"total_gross_worth": {
"description": "The total gross worth of the invoice",
"type": "FLOAT"
},
"items": {
"description": "The list of items with description, quantity and gross worth",
"type": "OBJECT",
"properties": {
"description": {
"description": "The description of the item",
"type": "STRING"
},
"quantity": {
"description": "The Qty of the item",
"type": "FLOAT"
},
"gross_worth": {
"description": "The gross worth of the item",
"type": "FLOAT"
}
}
}
},
"required": [
"invoice_number",
"date",
"total_gross_worth",
"items"
]
}
"""I also made sure to specify that I wanted to get “structured data” in the prompt and included exactly which data I wanted:

The final request was as follows:
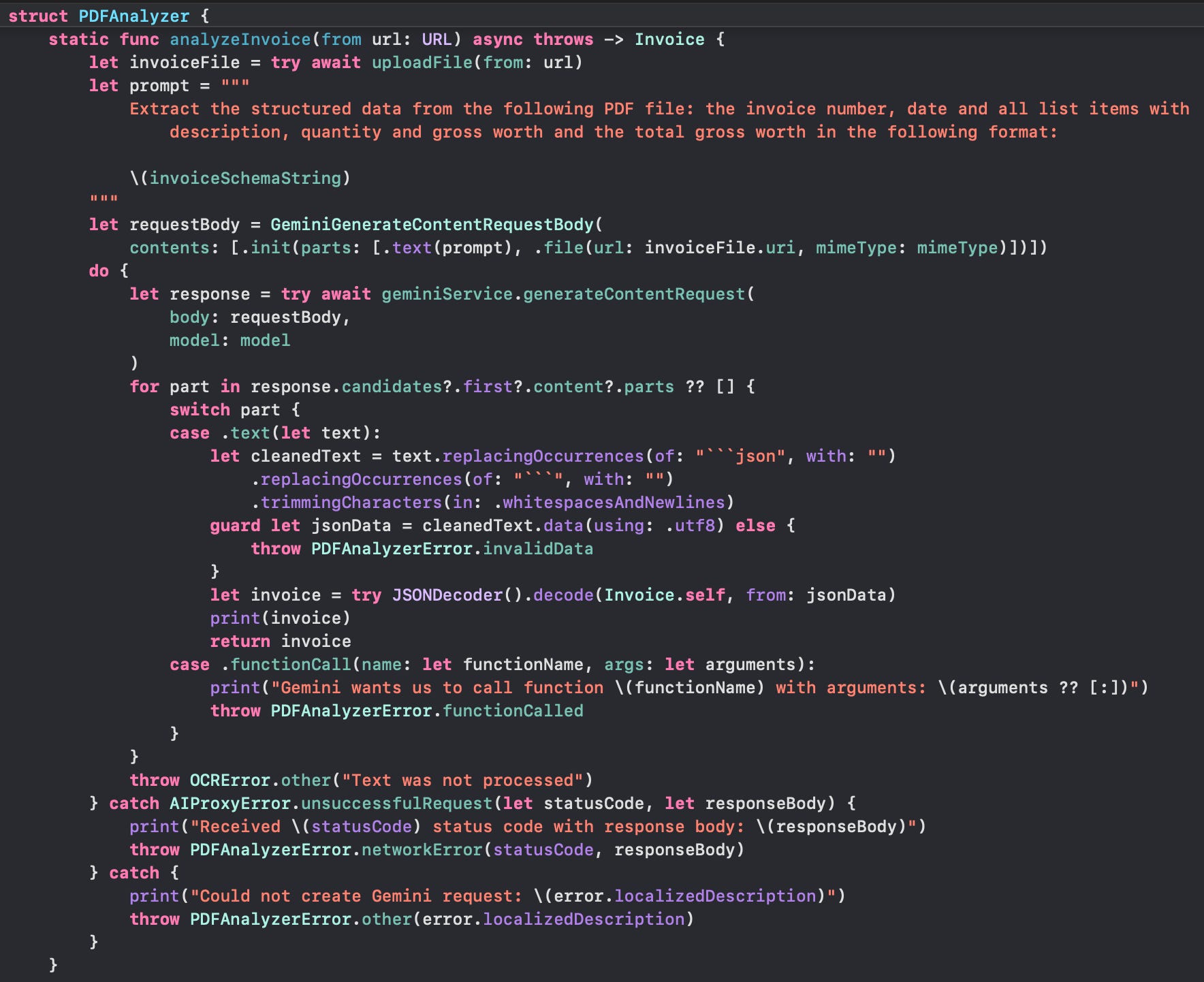
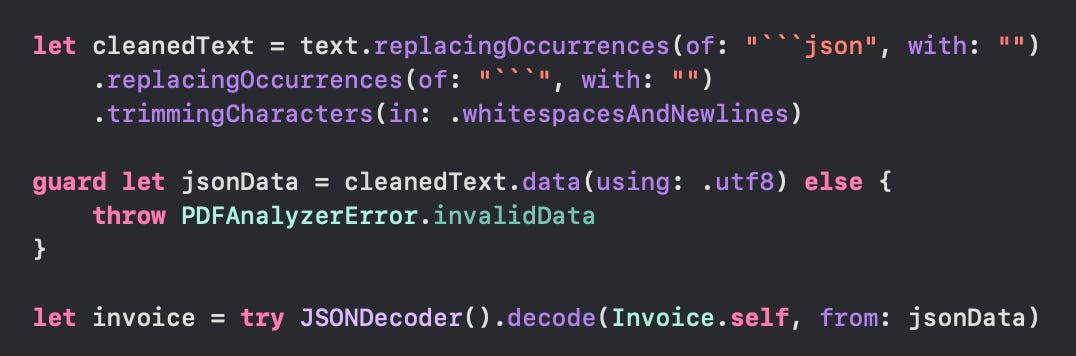
Note that the final result from the model was a string wrapped in markdown json syntax starting with ```json and ending with ```. So I had to remove it out before decoding the json string:
This approach worked well, although I would modify the prompt to be more specific, especially with data formatting for the final app.
Extract Structured Data from a Handwritten Document
The second example in Philipp Schmid’s blog post was extracting data from a handwritten tax form:

Just like with the typed invoice, we would specify the output schema in String format that will be injected into our prompt:
static let taxFormSchemaString = """
{
"type": "OBJECT",
"properties": {
"form_number": {
"description": "The Form Number",
"type": "STRING"
},
"start_date": {
"description": "Effective Date",
"type": "STRING"
},
"beginning_of_year": {
"description": "The plan liabilities beginning of the year",
"type": "FLOAT"
},
"end_of_year": {
"description": "The plan liabilities end of the year",
"type": "FLOAT"
}
},
"required": [
"form_number",
"start_date",
"beginning_of_year",
"end_of_year"
]
}
"""The Gemini request would then be the same as for the typed form - only modified with the updated form information:
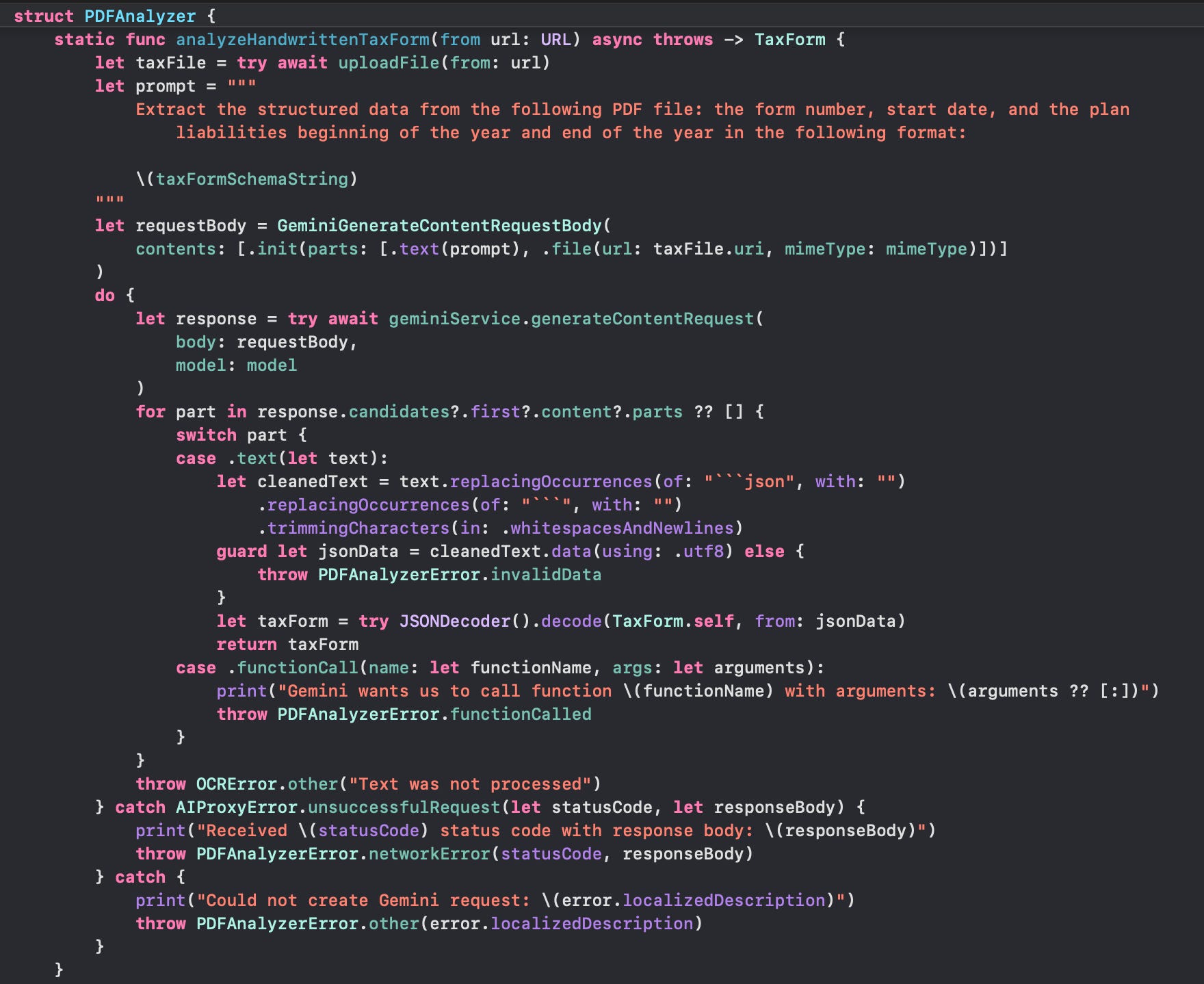
Counting Tokens
The Gemini 2.0 model has a super big context window of 1 million tokens. While this should be fine for small PDF files such as Invoices or Tax Documents, this might be a limitation for files such as large books, for example. To check token usage, it’s as simple as adding a few lines of code to your response code:
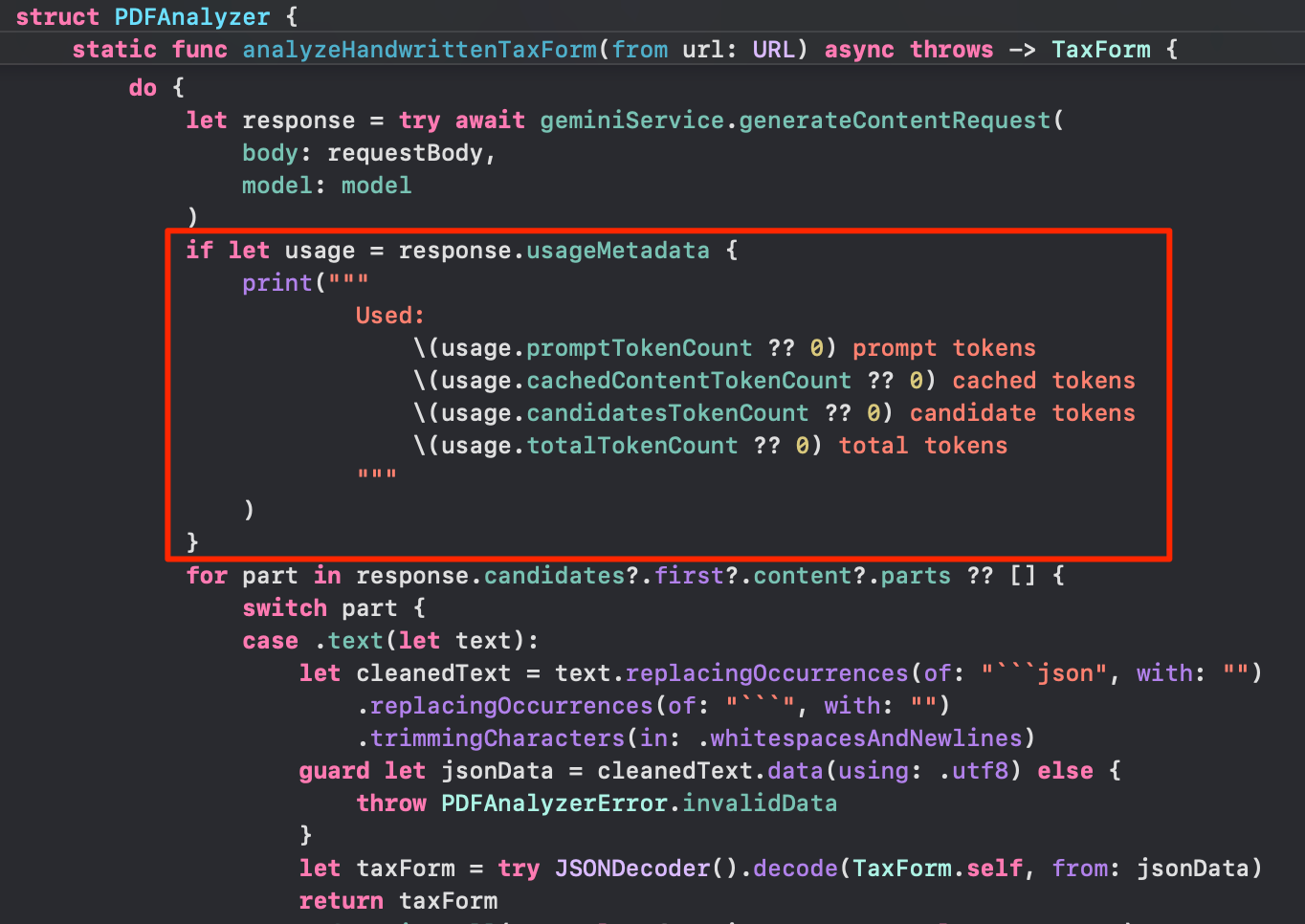
For the handwritten document in the example above, the token usage was as follows:
Used:
1518 prompt tokens
0 cached tokens
71 candidate tokens
1589 total tokensConclusion
By leveraging the Gemini 2.0 model, we can efficiently extract structured data from both typed and handwritten documents with minimal effort. While AIProxySwift currently lacks built-in support for structured outputs, manually injecting the JSON schema into the prompt proved to be a viable workaround.