
The Augmented LLM for Swift Developers
Learn how integrating retrieval systems, custom tools, and memory management can transform LLMs into dynamic, context-aware agents.

Large Language Models (LLMs) often create a sense of magic with their articulate and confident responses. However, a closer examination reveals that these outputs can sometimes stray from the truth or even be non-sensical. For instance, Swift developers using tools like ChatGPT or Claude may quickly encounter “hallucinated functions” — code elements that sound plausible yet simply do not exist. Similarly, a seasoned expert in any field can readily identify these inaccuracies.
This is primarily because LLMs are essentially sophisticated autocomplete engines, trained on a vast corpus of internet data. They work by taking in a large chunk of text and predicting a set of probable next tokens (parts of words) that will complete the text. One token is then selected and added to the original text, and the extended text is used as the input for predicting the next set of probable tokens, continuing until a final completion is generated and displayed to the user.
I highly recommend watching the visual representation and great explanation of this process by 3Blue1Brown if you haven’t already:
In this process, there’s no built-in fact-checking or grounding in truth—the LLM simply predicts the next most likely tokens (words) without any way to verify their accuracy.
This approach introduces additional challenges. For instance, LLMs are trained with a “cutoff date,” often relying on internet data from one or even two years ago. This means that any new information, such as breaking news or the latest iOS SDK/Swift updates announced at WWDC, won’t be part of the model’s prediction capabilities.
Another challenge is math. Since these models process language as tokens—essentially parts of words—they aren’t naturally equipped for performing mathematical calculations or accurately counting letters. They can only provide a correct answer if the exact calculation and its result were already present in their training data, allowing the model to predict it as the next likely token.
However, these models ARE very good at processing natural language as an input and responding back in natural language. So if they are augmented with the necessary enhancement by us as coders, the results are impressive. This “Augmented LLM” is the building block of most applications and agentic systems. So what is it and how does it work?
I first came across the term “The Augmented LLM” on Anthropic’s blog post on Building effective agents, which includes the following visualization:
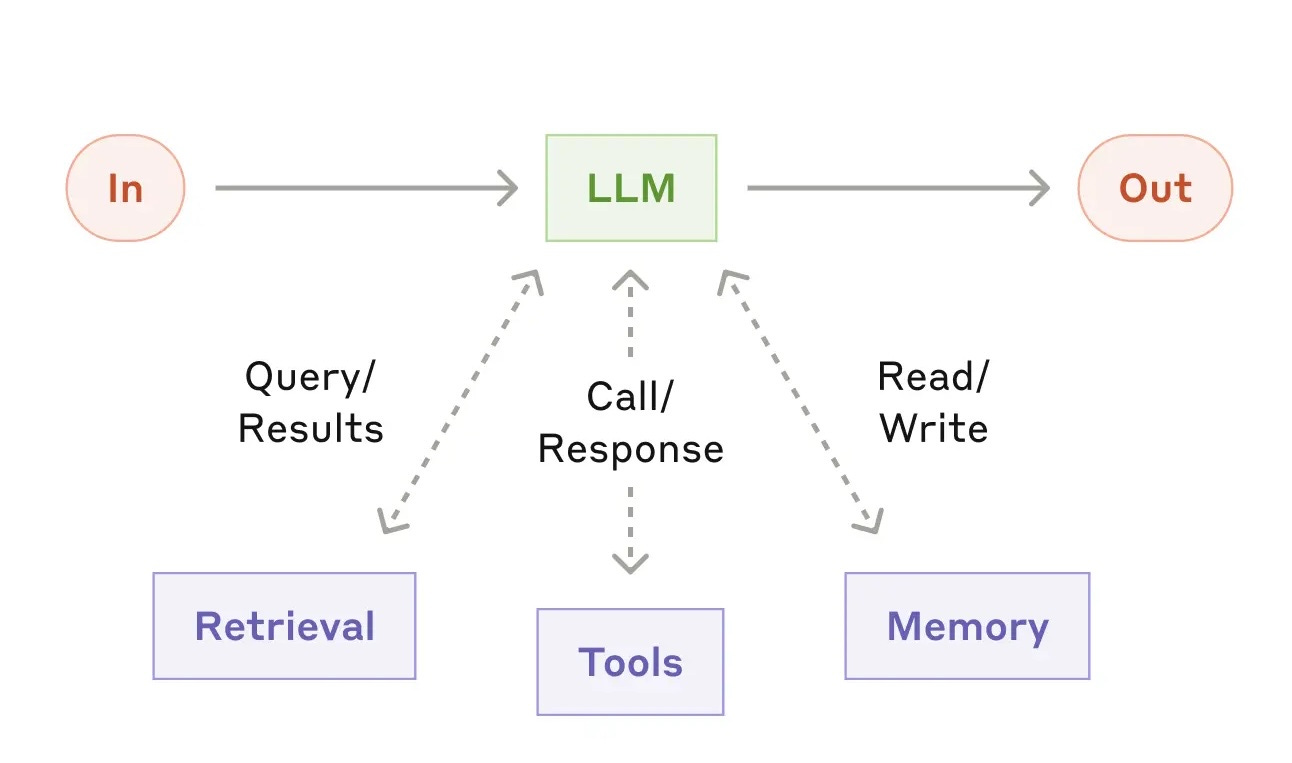
So let’s break it down step by step using a real-world example: building a “WeatherAgent,” a chat-based weather assistant.
Retrieval
As mentioned earlier, LLMs rely on internet data with a fixed cutoff date. This leads to two main issues: their information can become outdated, and they lack access to any personal or proprietary data outside their training set. This is where retrieval comes into play.
The goal of retrieval is to supply the LLM with the relevant information it needs. For instance, in a custom recipe app powered by an LLM, users might specify preferences like vegan options, allergies, or certain dislikes. During retrieval, your application would fetch these details from your proprietary database and include them as context in the user prompt, ensuring the LLM can provide more accurate and personalized responses. This augments the LLM with relevant data beyond its training set that is specific to your app, enabling it to generate text that is both contextually precise and tailored to your user’s unique requirements.
In the WeatherAgent app, the user’s location is the essential piece of context that enables seamless interaction. With this data, users can simply ask, “What’s the weather tonight?” without needing to specify their location each time. Leveraging iOS’s CoreLocation framework, the app can effortlessly retrieve the user’s current location, further enhancing the user experience.
Tools
LLMs don’t have access to real-time information—for example, they can’t fetch live weather data—because they function as advanced autocomplete engines. So, how can we augment them with current data? This is where tools come into play.
By integrating custom functions as tools, you can empower the LLM to retrieve live data when needed. For instance, if a user asks, “What’s the weather tonight?”, instead of fabricating an answer or stating that it lacks that data, the LLM can trigger a custom function like “getHourlyWeather” with the required parameters. Your app then executes this function to provide an accurate, real-time response.
The workflow would be as follows:
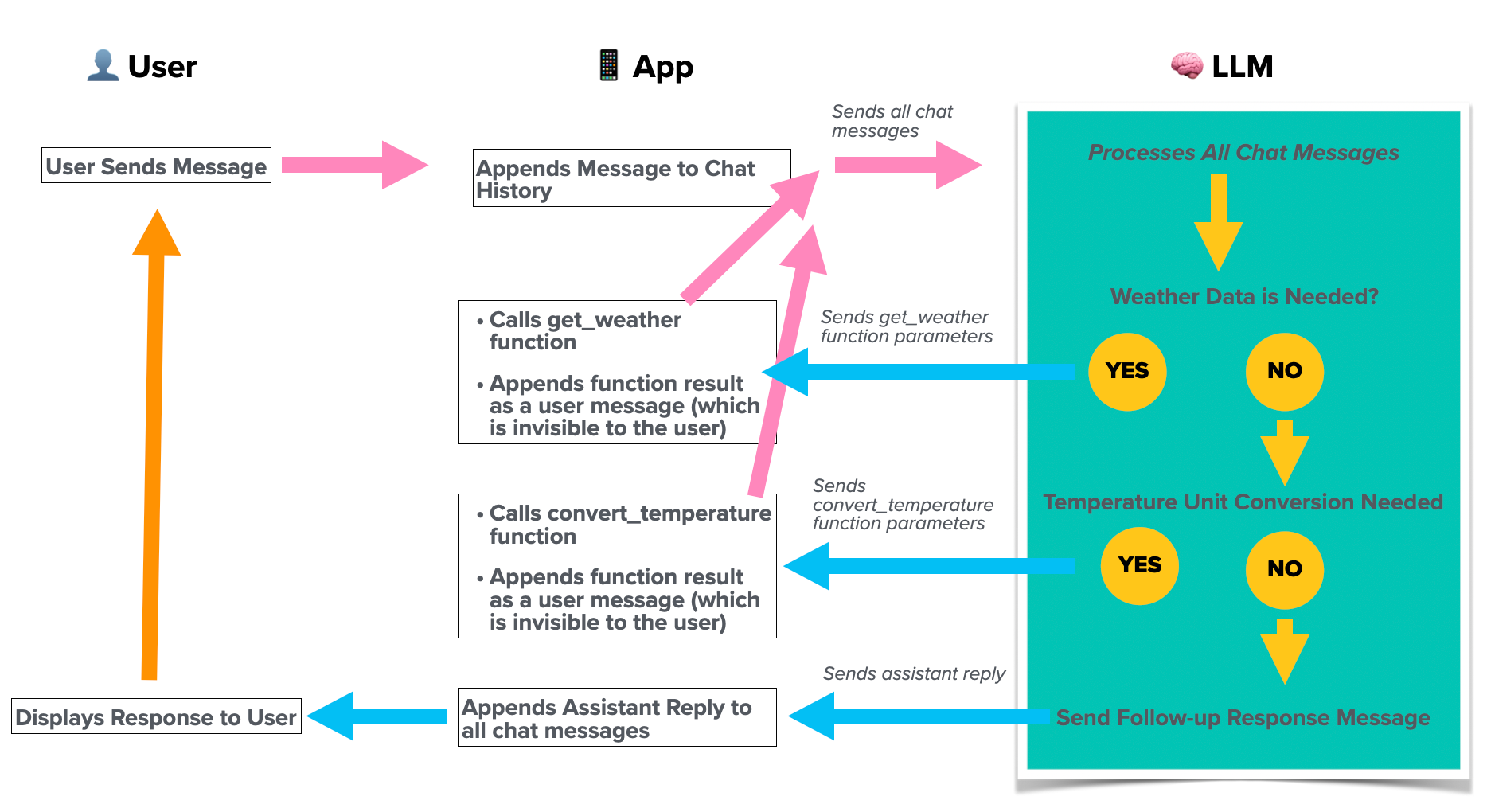
Using the WeatherKit API, your app will retrieve real-time weather data for the required location and return it back as context for the LLM to use to continue the conversation.
Read more about function calling here.
Note that functions can also be used to fetch any additional data needed to answer a user’s query, effectively merging retrieval with tool usage. For example, in web applications, if you provide your database specifications as context, the LLM can even generate the SQL query necessary to extract the relevant information from your database.
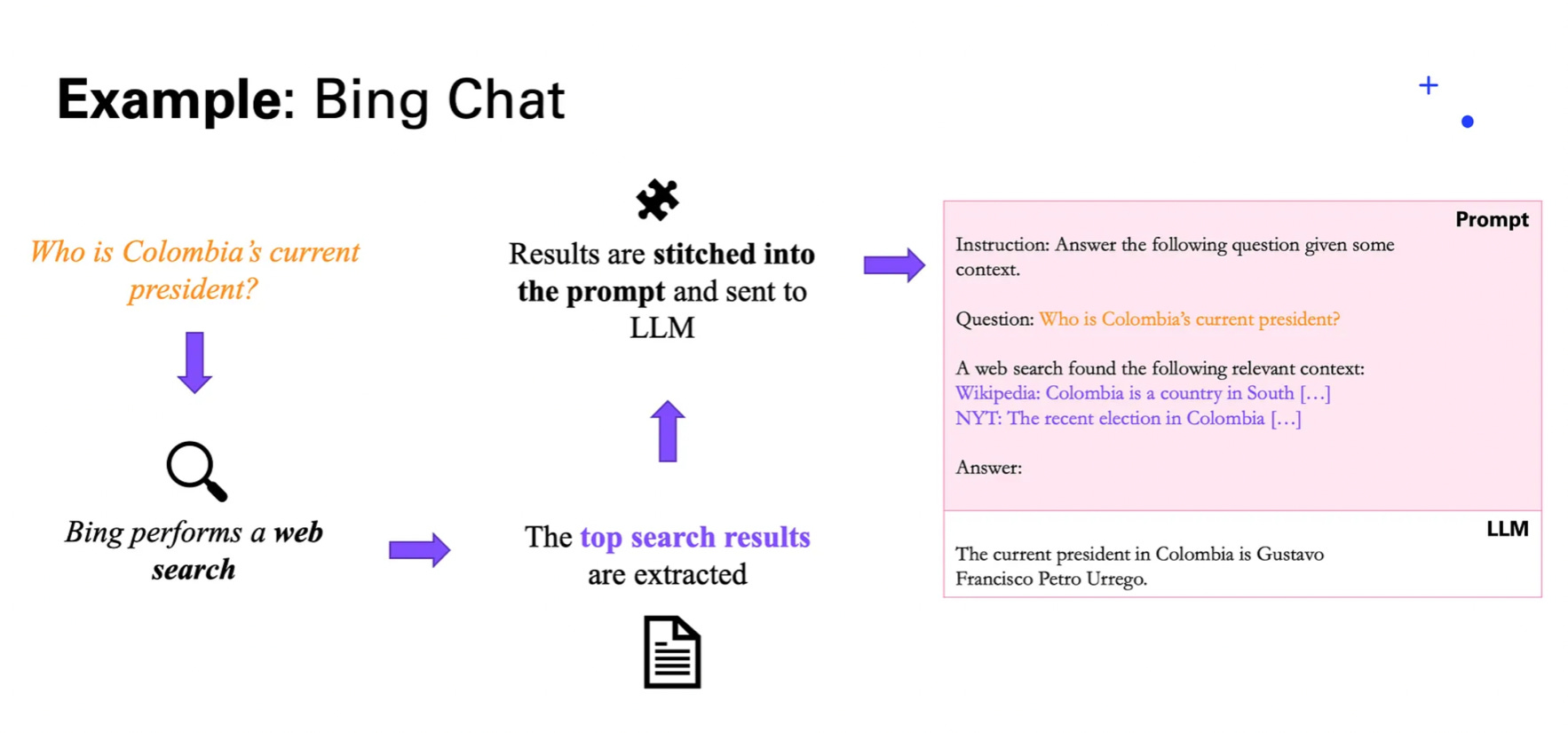
Another powerful tool is web search, offered by platforms like Google’s Gemini model, Perplexity, and OpenAI’s new Agent SDK. By leveraging these web search capabilities, the LLM can be augmented with the latest and most relevant information from the internet whenever needed.
Memory
LLMs take in text, perform calculations, and then output the next set of most likely tokens. They don’t have built-in memory, so they can’t recall previous interactions unless that context is included in the input. It’s up to the app to maintain the full conversation history as well as any user settings or preferences. This means that every time a user responds, the entire dialogue between the “user” and “assistant” must be provided to the LLM.
Conclusion
While LLMs offer a remarkable display of natural language fluency, their limitations—such as outdated information, lack of real-time data, and no built-in memory—highlight the need for thoughtful augmentation. By integrating retrieval systems, custom tools, and memory management strategies, developers can transform these models into dynamic, context-aware assistants that serve as the building blocks for agentic workflows.